linux user pwn 基础知识
环境搭建
虚拟机安装
- 镜像下载网站
- 为了避免环境问题建议 22.04 ,20.04,18.04,16.04 等常见版本 ubuntu 虚拟机环境各准备一份。注意定期更新快照以防意外。
- 虚拟机建议硬盘 256 G 以上,内存也尽量大一些。硬盘大小只是上界,256 G 不是真就占了 256 G,而后期如果硬盘空间不足会很麻烦。
- 更换 ubuntu 镜像源 ,建议先在
系统设置 → Software & Updates → Download from → 选择国内服务器例如阿里云(貌似不这样后续换源会出错),然后再sudo gedit /etc/apt/sources.list将镜像源中不高于当前系统版本的镜像复制进去(高于当前系统版本容易把apt搞坏)。 - Ubuntu 换源 error:The following signatures couldn’t be verified because the public key is not available 解决方法:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 5523BAEEB01FA116其中的5523BAEEB01FA116是根据错误提示写的。
基础工具
net-tools
ifconfig 查看网络配置需要安装 net-tools 。
1 | sudo apt install net-tools |
vim
1 | sudo apt install vim |
gedit
不习惯 vim 的可以使用 gedit 文本编辑器。
1 | sudo apt install gedit |
git
1 | sudo apt install git |
gcc
1 | sudo apt install gcc |
python
ipython 提供了很好的 python 交互命令行,建议安装。
1 | sudo apt install python2 |
另外有的版本 ubuntu 的不好安装 pip2 可以使用 get-pip.py 脚本安装。
1 | sudo apt install python3-pip |
ubuntu 22.04 的 ipython(python2)必须使用 pip2 安装:
1 | sudo pip2 install ipython |
docker
1 | sudo apt install docker.io |
默认情况下,Docker 命令需要使用 sudo 权限才能运行,这是因为 Docker 守护进程以 root 用户身份运行。然而,你可以通过以下步骤将当前用户添加到 Docker 用户组,从而允许在不使用 sudo 的情况下运行 Docker 命令:
确保当前用户属于
docker组:运行以下命令检查当前用户是否已添加到 docker 组:1
groups
在输出的组列表中查找
docker。如果没有找到docker组,请继续下一步。将当前用户添加到
docker组:运行以下命令将当前用户添加到docker组中(将<username>替换为你的用户名):1
sudo usermod -aG docker <username>
更新用户组更改:运行以下命令使用户组更改生效:
1
newgrp docker
重新登录或重启系统:要使用户组更改永久生效,你需要注销当前会话并重新登录,或者重启系统。
oh-my-zsh
安装 zsh
1 | sudo apt install zsh |
安装 oh-my-zsh
1 | sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)" |
设置 zsh 为默认 shell(重启虚拟机后生效)
1 | chsh -s /bin/zsh |
安装 oh-my-zsh 插件 zsh-autosuggestions ,zsh-syntax-highlighting
1 | git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions |
编辑 ~/.zshrc 添加插件:
1 | plugins=( |
更新:
1 | omz update |
wsl
WSL (Windows Subsystem for Linux) 是微软为 Windows 用户提供的一种兼容层,允许用户在 Windows 操作系统上运行 Linux 环境(包括大部分命令行工具、应用程序和服务),而不需要安装虚拟机或双系统。简单来说,WSL 让你在 Windows 上运行 Linux 程序,就像它们是原生程序一样。
WSL 目前有 WSL1 和 WSL2 两个版本:
WSL1 :最初的版本,提供 Linux 环境,运行 Linux 程序,速度较快但功能较有限。
WSL2 :通过在 Windows 上虚拟化完整的 Linux 内核,提供更强大的功能和更高的兼容性,特别适合需要容器、Docker 或更复杂的 Linux 功能的开发工作。
由于 WSL2 和虚拟机的部分设置冲突,因此这里建议安装 WSL1。具体安装过程如下:
安装 WSL 1 或 WSL 2 : 你可以通过 PowerShell 运行以下命令来安装 WSL:
1
wsl --install
选择 Linux 发行版 : 安装后,你可以从 Microsoft Store 下载你喜欢的 Linux 发行版(如 Ubuntu、Debian 等)。我这里安装的是 Ubuntu 22.04。
启用 Windows 功能 :下载好 Linux 发行版后在应用商店选择打开该 Linux,此时会弹出系统安装的命令窗口。但正常情况下这一步会出现一些报错,你需要启用部分 Windows 功能来避免这些报错。
0x80370114 错误 :这个报错说明未启用“虚拟机平台 (Virtual Machine Platform)”或“Windows 子系统 for Linux”功能。你需要打开 PowerShell(以管理员身份运行),依次执行以下命令并重启电脑:
1
2dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart0x80370102 错误 :这个报错表示虚拟化功能未启用,或者 Windows 中的 虚拟机平台 (Virtual Machine Platform) 功能未启用。
如果是安装 WSL2 则需要打开 PowerShell(以管理员身份运行),然后执行以下命令开启 Hyper-V 功能并重启电脑。
1
dism.exe /online /enable-feature /featurename:Microsoft-Hyper-V-All /all /norestart
之后还要打开 任务管理器,切换到“性能”选项卡,选择“CPU”,查看右下角“虚拟化”是否显示为 已启用。如果未启用还要在重启的时候进 BIOS 开启 CPU 的虚拟化选项。
如果是安装 WSL1 则只需要将 WSL 的版本设置为 1 即可。
1
wsl --set-default-version 1
解决 WSL 中 DNS 炸的问题:
1 | sudo bash -c 'cat > /etc/resolv.conf <<EOF |
pwn 相关工具
clion
clion 是一款 C\C++ 的 IDE ,可以用来阅读 glibc 源码的工具,这款工具对宏展开,符号跳转,结构体大小以及成员偏移计算都有很好的支持。这款软件需要付费使用,不过可以某宝搞一个教育邮箱。
首先用打开 debug_glibc 解压后的 glibc 源码,这里有以下几点需要注意:
- 源码在对应版本的
source目录下。 - 最好不要使用解压到默认
\glibc路径下的源码,因为源码调试与行号绑定,阅读源码可能会修改到源码。 - 这里用
debug_glibc中的源码是因为这里的源码是编译过的,clion 分析代码需要编译的配置文件。
然后这里我们看到 Makefile 没有正确导入:
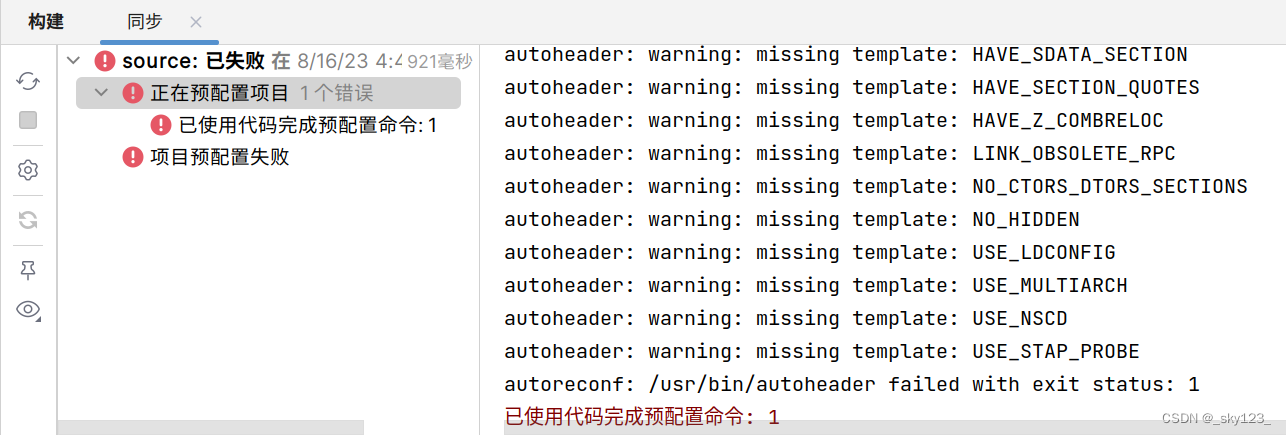
在较新版本的 clion 中位于 source 根目录下的 autoreconf 的配置文件 configure.ac 配置有问题,需要改成以下内容(这个主要看版本,有时默认的就好使):
1 | GLIBC_PROVIDES dnl See aclocal.m4 in the top level source directory. |
另外还需要右键 Makefile 设置在命令后面添加 --disable-sanity-checks 。另外构建目标要填 all ,否则 clion 分析的源码的不全。
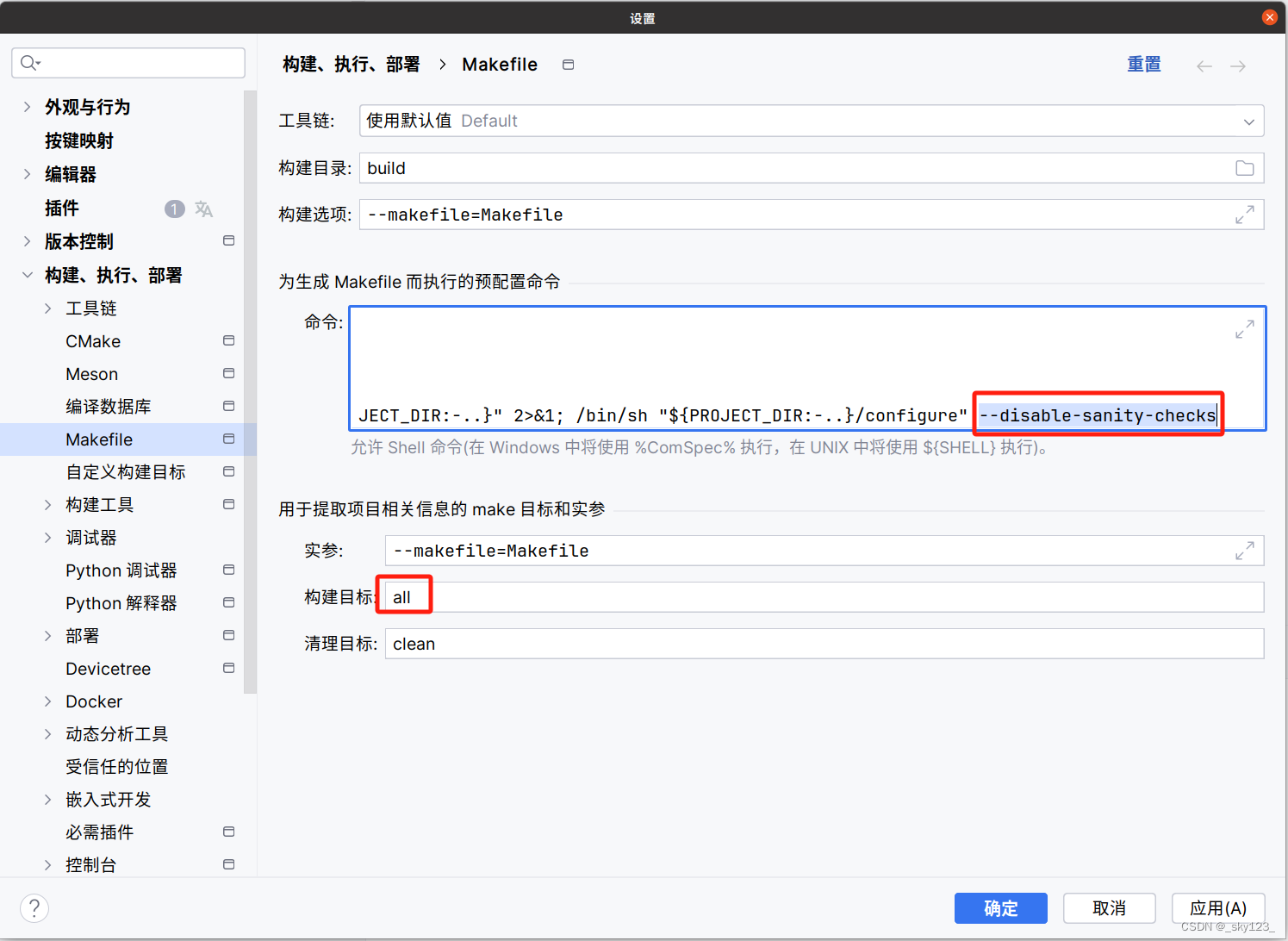
完整预配置命令如下:
1 |
|
之后右键重新加载 Makefile 项目。
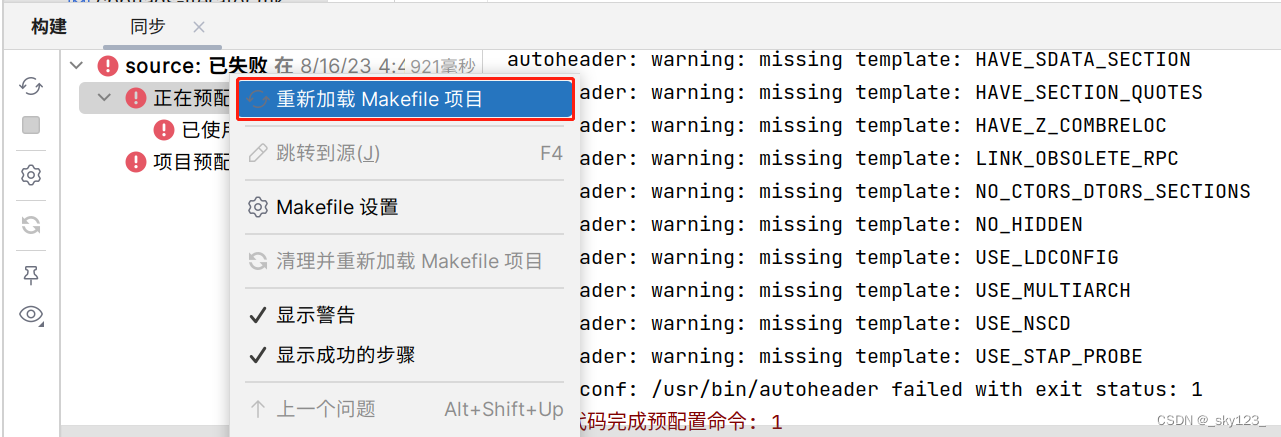
不勾选清理项目。
如果最后这样说明导入成功,之后耐心等待项目导入完毕即可。
gdb
1 | sudo apt-get install gdb gdb-multiarch |
主要有 pwndbg,peda,gef ,这里我常用的是 pwndbg 。对于一些版本过于古老导致环境装不上的可以尝试一下 peda 。
先将三个项目的代码都拉取下来。
1 | git clone https://github.com/longld/peda.git |
pwndbg 需要运行初始化脚本。
1 | cd pwndbg |
setup.sh慢/超时主要是两段:
pip install uv默认去pypi.org拉 20+MB 的 wheel,在国内经常很慢;清华 TUNA 这类镜像可以用.../simple来加速(simple不能少,而且要用 https)。- 后面的
uv sync也默认走 PyPI;而且 uv 不会自动沿用 pip 的镜像配置,需要单独给 uv 配 index(例如UV_DEFAULT_INDEX/UV_INDEX_URL),并且可以通过UV_HTTP_TIMEOUT/UV_HTTP_RETRIES调大超时与重试来缓解慢网超时。下面是把
setup.sh改成支持一键使用国内 PyPI 镜像的完整版本(同时把一开始那个 “Error: ‘uv’ binary not found.” 的噪音也抑制掉了;它本来只是common.sh早于 venv 创建而已,不是致命错误)。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
set -e
# -----------------------------
# Pwndbg dev setup helper (patched for CN mirrors)
#
# New flags:
# --cn Use a China-friendly PyPI mirror for BOTH pip (uv install) and uv (uv sync)
# --pypi-mirror URL Override the PyPI/simple index URL (works with --cn too)
# --cn-apt (Ubuntu only) Switch archive.ubuntu.com -> a CN Ubuntu mirror (backup first)
# --cn-apt-security (Ubuntu only) Also switch security.ubuntu.com -> the CN mirror (NOT recommended on prod)
# --apt-mirror URL Override the Ubuntu mirror base (Ubuntu only; used with --cn-apt*)
# --update Same as upstream: do not touch ~/.gdbinit
#
# You can also configure mirrors via environment variables:
# PWNDBG_PYPI_MIRROR="https://pypi.tuna.tsinghua.edu.cn/simple"
# PWNDBG_APT_MIRROR="https://mirrors.tuna.tsinghua.edu.cn/ubuntu"
# UV_HTTP_TIMEOUT=600 UV_HTTP_RETRIES=10 (optional)
#
# -----------------------------
SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
# The upstream scripts/common.sh prints "Error: 'uv' binary not found." before we create the venv.
# That's harmless but confusing. We temporarily set PWNDBG_NO_UV=1 while sourcing, to silence it.
__OLD_PWNDBG_NO_UV="${PWNDBG_NO_UV-}"
export PWNDBG_NO_UV=1
# shellcheck source=/dev/null
source "${SCRIPT_DIR}/scripts/common.sh"
if [[ -n "${__OLD_PWNDBG_NO_UV}" ]]; then
export PWNDBG_NO_UV="${__OLD_PWNDBG_NO_UV}"
else
unset PWNDBG_NO_UV
fi
unset __OLD_PWNDBG_NO_UV
# If we are root in a container and `sudo` doesn't exist, overwrite sudo with a passthrough.
if ! hash sudo 2> /dev/null && whoami | grep -q root; then
sudo() { ${*}; }
fi
# Helper functions
linux() { uname | grep -iqs Linux; }
osx() { uname | grep -iqs Darwin; }
# -----------------------------
# Mirror helpers (CN-friendly)
# -----------------------------
DEFAULT_CN_PYPI_MIRROR="https://pypi.tuna.tsinghua.edu.cn/simple"
DEFAULT_CN_UBUNTU_MIRROR="https://mirrors.tuna.tsinghua.edu.cn/ubuntu"
USE_CN_MIRROR=0
USE_CN_APT=0
USE_CN_APT_SECURITY=0
# Allow overriding via environment variables
PWNDBG_PYPI_MIRROR="${PWNDBG_PYPI_MIRROR-}"
PWNDBG_APT_MIRROR="${PWNDBG_APT_MIRROR-}"
# Derived pip options (only used for installing uv with pip)
PIP_TIMEOUT="${PIP_TIMEOUT-120}"
PIP_RETRIES="${PIP_RETRIES-10}"
# Derived uv options (only used when --cn is enabled unless user sets them externally)
UV_HTTP_TIMEOUT_DEFAULT="${UV_HTTP_TIMEOUT-600}"
UV_HTTP_RETRIES_DEFAULT="${UV_HTTP_RETRIES-10}"
get_host_from_url() {
# Extract host from a URL like https://example.com/path -> example.com
echo "$1" | sed -E 's@^[a-zA-Z]+://([^/]+)/?.*$@\1@'
}
enable_python_mirror_env() {
# Configure uv to use a custom index (mirror) + safer timeout/retry defaults.
# uv supports UV_DEFAULT_INDEX / UV_INDEX_URL and UV_HTTP_TIMEOUT / UV_HTTP_RETRIES. (Docs: Astral uv)
local mirror_url="$1"
export UV_DEFAULT_INDEX="${mirror_url}"
# Backwards compatibility for older uv (deprecated but still recognized):
export UV_INDEX_URL="${mirror_url}"
# Avoid random timeouts on slow links
export UV_HTTP_TIMEOUT="${UV_HTTP_TIMEOUT_DEFAULT}"
export UV_HTTP_RETRIES="${UV_HTTP_RETRIES_DEFAULT}"
# For pip (used only to fetch the 'uv' wheel into the venv)
export PIP_DEFAULT_TIMEOUT="${PIP_TIMEOUT}"
export PIP_DISABLE_PIP_VERSION_CHECK=1
}
apply_ubuntu_apt_mirror() {
# Only for Ubuntu, and only when user explicitly asked via --cn-apt / --cn-apt-security.
local mirror_base="$1" # e.g. https://mirrors.tuna.tsinghua.edu.cn/ubuntu
local also_security="$2" # 0/1
local files=()
[[ -f /etc/apt/sources.list ]] && files+=("/etc/apt/sources.list")
[[ -f /etc/apt/sources.list.d/ubuntu.sources ]] && files+=("/etc/apt/sources.list.d/ubuntu.sources")
if [[ ${#files[@]} -eq 0 ]]; then
echo "[!] No Ubuntu APT source file found to patch. Skipping APT mirror change."
return 0
fi
echo "[*] Applying Ubuntu APT mirror: ${mirror_base}"
if [[ "${also_security}" == "1" ]]; then
echo "[!] NOTE: You enabled switching *security* updates to the mirror."
echo " Mirrors may lag behind official security updates; consider leaving security.ubuntu.com unchanged on production machines."
fi
for f in "${files[@]}"; do
# Backup once
if [[ ! -f "${f}.pwndbg.bak" ]]; then
sudo cp -a "${f}" "${f}.pwndbg.bak" || true
echo "[*] Backup created: ${f}.pwndbg.bak"
fi
# Replace archive.ubuntu.com (and regional variants like xx.archive.ubuntu.com)
sudo sed -i \
-e "s@http://archive.ubuntu.com/ubuntu@${mirror_base}@g" \
-e "s@https://archive.ubuntu.com/ubuntu@${mirror_base}@g" \
-e "s@http://[a-z][a-z]\\.archive.ubuntu.com/ubuntu@${mirror_base}@g" \
-e "s@https://[a-z][a-z]\\.archive.ubuntu.com/ubuntu@${mirror_base}@g" \
"${f}" || true
if [[ "${also_security}" == "1" ]]; then
sudo sed -i \
-e "s@http://security.ubuntu.com/ubuntu@${mirror_base}@g" \
-e "s@https://security.ubuntu.com/ubuntu@${mirror_base}@g" \
"${f}" || true
fi
done
}
# -----------------------------
# Package manager installers
# -----------------------------
install_apt() {
sudo apt-get update || true
sudo apt-get install -y git gdb gdbserver python3-dev python3-venv python3-setuptools
sudo apt-get install -y libc6-dbg
}
install_dnf() {
sudo dnf update || true
sudo dnf -y install git gdb gdb-gdbserver python3-devel
sudo dnf -y debuginfo-install glibc
}
install_xbps() {
sudo xbps-install -Su
sudo xbps-install -Sy gdb gcc python-devel python3-devel glibc-devel make curl
sudo xbps-install -Sy glibc-dbg
}
install_swupd() {
sudo swupd update || true
sudo swupd bundle-add gdb python3-basic make c-basic curl
}
install_zypper() {
sudo zypper mr -e repo-oss-debug || sudo zypper mr -e repo-debug
sudo zypper refresh || true
sudo zypper install -y gdb gdbserver python-devel python3-devel glib2-devel make glibc-debuginfo curl
sudo zypper install -y python2-pip || true # skip py2 installation if it doesn't exist
if uname -m | grep -q x86_64; then
sudo zypper install -y glibc-32bit-debuginfo || true
fi
}
install_emerge() {
sudo emerge --oneshot --deep --newuse --changed-use --changed-deps dev-lang/python dev-debug/gdb
}
install_oma() {
sudo oma refresh || true
sudo oma install -y gdb python-3 glib make glibc-dbg curl
if uname -m | grep -q x86_64; then
sudo oma install -y glibc+32-dbg || true
fi
}
install_pacman() {
read -p "Do you want to do a full system update? (y/n) [n] " answer
# user want to perform a full system upgrade
answer=${answer:-n} # n is default
if [[ "$answer" == "y" ]]; then
sudo pacman -Syu || true
fi
sudo pacman -S --noconfirm --needed git gdb python which debuginfod curl
if [ -z "$UPDATE_MODE" ]; then
if ! grep -qs "^set debuginfod enabled on" ~/.gdbinit; then
echo "set debuginfod enabled on" >> ~/.gdbinit
echo "[*] Added 'set debuginfod enabled on' to ~/.gdbinit"
fi
fi
}
install_freebsd() {
sudo pkg install git gdb python py39-pip cmake gmake curl
which rustc || sudo pkg install rust
}
usage() {
echo "Usage: $0 [--update] [--cn] [--pypi-mirror URL] [--cn-apt] [--cn-apt-security] [--apt-mirror URL]"
echo ""
echo " --cn Use a CN PyPI mirror for pip+uv (default: ${DEFAULT_CN_PYPI_MIRROR})"
echo " --pypi-mirror URL Override the PyPI/simple index URL used for --cn"
echo " --cn-apt (Ubuntu) Switch archive.ubuntu.com -> CN Ubuntu mirror (backup first)"
echo " --cn-apt-security (Ubuntu) Also switch security.ubuntu.com -> mirror (NOT recommended on prod)"
echo " --apt-mirror URL Override Ubuntu mirror base (default: ${DEFAULT_CN_UBUNTU_MIRROR})"
echo " --update Install/update deps without checking ~/.gdbinit"
echo ""
echo "Env vars (optional):"
echo " PWNDBG_PYPI_MIRROR, PWNDBG_APT_MIRROR, UV_HTTP_TIMEOUT, UV_HTTP_RETRIES, PIP_TIMEOUT, PIP_RETRIES"
}
UPDATE_MODE=
while [[ $# -gt 0 ]]; do
case "$1" in
--update)
UPDATE_MODE=1
shift
;;
--cn)
USE_CN_MIRROR=1
shift
;;
--pypi-mirror)
if [[ $# -lt 2 ]]; then
echo "Missing value for --pypi-mirror"
exit 1
fi
PWNDBG_PYPI_MIRROR="$2"
shift 2
;;
--cn-apt)
USE_CN_APT=1
shift
;;
--cn-apt-security)
USE_CN_APT=1
USE_CN_APT_SECURITY=1
shift
;;
--apt-mirror)
if [[ $# -lt 2 ]]; then
echo "Missing value for --apt-mirror"
exit 1
fi
PWNDBG_APT_MIRROR="$2"
shift 2
;;
-h | --help)
usage
exit 0
;;
*)
echo "Unknown argument: $1"
usage
exit 1
;;
esac
done
PYTHON=''
if osx; then
echo "Not supported on macOS. Please use one of the alternative methods listed at:"
echo "https://pwndbg.re/dev/contributing/setup-pwndbg-dev/"
exit 1
fi
# Decide mirror URLs
if [[ "${USE_CN_MIRROR}" == "1" && -z "${PWNDBG_PYPI_MIRROR}" ]]; then
PWNDBG_PYPI_MIRROR="${DEFAULT_CN_PYPI_MIRROR}"
fi
if [[ "${USE_CN_APT}" == "1" && -z "${PWNDBG_APT_MIRROR}" ]]; then
PWNDBG_APT_MIRROR="${DEFAULT_CN_UBUNTU_MIRROR}"
fi
# Apply mirror env early (affects pip + uv later)
if [[ "${USE_CN_MIRROR}" == "1" ]]; then
echo "[*] Using CN PyPI mirror for pip+uv: ${PWNDBG_PYPI_MIRROR}"
enable_python_mirror_env "${PWNDBG_PYPI_MIRROR}"
fi
if linux; then
distro=$(grep "^ID=" /etc/os-release | cut -d'=' -f2 | sed -e 's/\"//g')
case $distro in
"ubuntu")
if [[ "${USE_CN_APT}" == "1" ]]; then
apply_ubuntu_apt_mirror "${PWNDBG_APT_MIRROR}" "${USE_CN_APT_SECURITY}"
fi
install_apt
;;
"fedora")
install_dnf
;;
"clear-linux-os")
install_swupd
;;
"opensuse-leap" | "opensuse-tumbleweed")
install_zypper
;;
"arch" | "archarm" | "endeavouros" | "manjaro" | "garuda" | "cachyos" | "archcraft" | "artix")
install_pacman
echo "Logging off and in or conducting a power cycle is required to get debuginfod to work."
echo "Alternatively you can manually set the environment variable: DEBUGINFOD_URLS=https://debuginfod.archlinux.org"
;;
"void")
install_xbps
;;
"gentoo")
install_emerge
;;
"freebsd")
install_freebsd
;;
"aosc")
install_oma
;;
*) # we can add more install command for each distros.
echo "\"$distro\" is not supported distro. Will search for 'apt', 'dnf' or 'pacman' package managers."
if hash apt; then
install_apt
elif hash dnf; then
install_dnf
elif hash pacman; then
install_pacman
else
echo "\"$distro\" is not supported and your distro don't have a package manager that we support currently."
exit 2
fi
;;
esac
fi
if ! hash gdb; then
echo "Could not find gdb in $PATH"
exit 3
fi
# Find the Python used in compilation by GDB.
PYVER=$(gdb -batch -q --nx -ex 'pi import sysconfig; print(sysconfig.get_config_var("VERSION"))')
PYTHON=$(gdb -batch -q --nx -ex 'pi import sysconfig; print(sysconfig.get_config_vars().get("EXENAME", sysconfig.get_config_var("BINDIR")+"/python"+sysconfig.get_config_var("VERSION")+sysconfig.get_config_var("EXE")))')
if [ ! -x "$PYTHON" ]; then
echo "Error: '$PYTHON' does not exist or is not executable."
echo ""
echo "It looks like GDB is using a different Python version than the one installed via the package manager."
echo ""
echo "Possible solutions:"
echo " 1. Try installing 'python$PYVER' manually using your package manager."
echo " Example (for Debian/Ubuntu/Kali): 'sudo apt install python$PYVER'"
echo " Example (for Fedora/RHEL): 'sudo dnf install python$PYVER'"
echo " 2. Verify your GDB configuration and ensure it supports the correct Python version."
echo ""
echo "After making the necessary changes, rerun ./setup.sh"
exit 1
fi
# Check python version supported: <3.10, 3.99>
is_supported=$(echo "$PYVER" | grep -E '3\.(10|11|12|13|14|15|16|17|18|19|[2-9][0-9])' || true)
if [[ -z "$is_supported" ]]; then
echo "Your system has unsupported python version. Please use older pwndbg release:"
echo "'git checkout 2024.08.29' - python3.8, python3.9"
echo "'git checkout 2023.07.17' - python3.6, python3.7"
exit 4
fi
# Create the python virtual environment
echo "Creating virtualenv in path: ${PWNDBG_VENV_PATH}"
${PYTHON} -m venv -- ${PWNDBG_VENV_PATH}
# Activate venv
# shellcheck source=/dev/null
source "${PWNDBG_VENV_PATH}/bin/activate"
# Install uv inside the venv (use mirror if enabled)
echo "Installing uv into venv..."
if [[ "${USE_CN_MIRROR}" == "1" ]]; then
python -m pip install --upgrade uv \
--index-url "${PWNDBG_PYPI_MIRROR}" \
--timeout "${PIP_TIMEOUT}" \
--retries "${PIP_RETRIES}"
else
python -m pip install --upgrade uv
fi
UV_BIN="${PWNDBG_VENV_PATH}/bin/uv"
if [[ ! -x "${UV_BIN}" ]]; then
# fallback, but normally venv/bin/uv should exist
if command -v uv > /dev/null 2>&1; then
echo "Warning: Falling back to 'uv' found in PATH." >&2
UV_BIN="$(command -v uv)"
else
echo "Error: 'uv' not found after installation. Check your pip/venv setup." >&2
exit 5
fi
fi
# Install dependencies
echo "Installing dependencies.."
# uv will use UV_DEFAULT_INDEX / UV_HTTP_TIMEOUT / UV_HTTP_RETRIES if exported above.
"${UV_BIN}" sync --extra gdb --extra lldb --quiet
if [ -z "$UPDATE_MODE" ]; then
if grep -qs '^[^#]*source.*pwndbg/gdbinit.py' ~/.gdbinit; then
echo 'Pwndbg is already sourced in ~/.gdbinit .'
else
# Load Pwndbg into GDB on every launch.
echo "source $PWD/gdbinit.py" >> ~/.gdbinit
echo "[*] Added 'source $PWD/gdbinit.py' to ~/.gdbinit so that Pwndbg will be loaded on every launch of GDB."
fi
echo "Please set the PWNDBG_NO_AUTOUPDATE environment variable to any value"
echo "to disable the automatic updating of dependencies when Pwndbg is loaded."
fi用法示例:
2
3
4
5
6
7
8
9
10
11
./setup.sh --cn
# 2) 自己指定 PyPI 镜像(例如阿里云)
./setup.sh --cn --pypi-mirror https://mirrors.aliyun.com/pypi/simple/
# 3) (可选)Ubuntu APT 也换源:只换 archive,不动 security(更稳妥)
./setup.sh --cn --cn-apt
# 4) (不建议生产机)连 security 源也换到镜像
./setup.sh --cn --cn-apt-security
gdb 在启动的时候会读取当前用户的主目录的 .gdbinit 文件进行 gdb 插件的初始化,通常来说使用默认的配置即可:
1 | source /home/sky123/tools/pwndbg/gdbinit.py |
注意
以普通用权限和管理员权限启动 gdb 时读取的 .gdbinit 文件的路径是不同的,普通权限读取的是 /home/<username>/.gdbinit 而管理员权限读取的是 /root/.gdbinit 。
pwndbg 安装 ghidra 插件可以支持代码反编译(
虽然没啥用)
安装
r2pipe库
下载安装 radere2 项目
2
3
cd radare2
sudo sys/install.sh下载编译安装 r2ghidra 项目
2
3
4
5
6
cd r2ghidra
sudo ./preconfigure
sudo ./configure
sudo make -j16
sudo make install
没有调试插件的时候可以使用下面这套命令应急。最好放到 ~/.gdbinit 文件,如果在命令行中使用则只能逐行粘贴。
1 | set pagination off |
pwntools
注意我这里的 pwntools 是 python2 版本的,需要指定为 4.9.0 ,因为高版本的 pwntools 已经不支持 python2 了(具体来说是高版本的 pwntools 必须依赖 unicorn 2.x.x ,而 unicorn 2.x.x 只支持 python3)。
1 | pip install pwntools==4.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple |
如果已经装了 pwntools 需要先卸载干净再重新安装,否则更改版本无效(最好不带 sudo 也来一遍确保卸载干净)。
1 | sudo pip2 uninstall pwntools |
这样安装的 pwntools 的 plt 功可能无法正常使用,需要手动安装 Unicorn 库。
1 | pip install unicorn==1.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple |
当然这样做的代价是一些特殊架构老版本的 pwntools 不支持,这时候最好换 python3 的 pwntools 。
gadget 搜索工具
ROPgdbget
安装:
1 | git clone https://github.com/JonathanSalwan/ROPgadget.git |
使用:
1 | ROPgadget --binary ntdll.dll > rop |
有时候 ROPgadget 会出现如下报错:
1 | ROPgadget --binary init_60D_fwf > rop |
此时需要重新安装 capstone:
1 | sudo pip uninstall capstone |
如果出现这个报错:
1 | ➜ ~ ROPgadget |
这里需要将 ROPGadget 安装目录下的 script 目录拷贝到 /home/ubuntu/.local/lib/python3.10/site-packages/ROPGadget-7.5.dist-info 中。
1 | cd ROPGadget |
ropper
ropper 可以和 ROPgadget 配合使用,因为有的 gadget 使用 ROPgadget 搜不到,例如 arm32 架构的 Thumb 模式 gadget。
安装:
在 pypi 的 ropper 官网上下载 ropper
运行安装脚本完成 ropper 安装
1
sudo python3 setup.py install
使用:
1
ropper --file ./pwn --nocolor > rop
one_gadget
用于搜索 libc 中能够实现 execve("/bin/sh", (char *[2]) {"/bin/sh", NULL}, NULL); 的效果的跳转地址,由于是采用特征匹配的方法,因此只能是在 libc 中查找。
安装:
1
2sudo apt install -y ruby ruby-dev
sudo gem install one_gadget使用:可以查找到 gadget 地址以及条件限制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24➜ ~ one_gadget /lib/x86_64-linux-gnu/libc.so.6
0x50a37 posix_spawn(rsp+0x1c, "/bin/sh", 0, rbp, rsp+0x60, environ)
constraints:
rsp & 0xf == 0
rcx == NULL
rbp == NULL || (u16)[rbp] == NULL
0xebcf1 execve("/bin/sh", r10, [rbp-0x70])
constraints:
address rbp-0x78 is writable
[r10] == NULL || r10 == NULL
[[rbp-0x70]] == NULL || [rbp-0x70] == NULL
0xebcf5 execve("/bin/sh", r10, rdx)
constraints:
address rbp-0x78 is writable
[r10] == NULL || r10 == NULL
[rdx] == NULL || rdx == NULL
0xebcf8 execve("/bin/sh", rsi, rdx)
constraints:
address rbp-0x78 is writable
[rsi] == NULL || rsi == NULL
[rdx] == NULL || rdx == NULL如果
one_gadget在一个版本的 Ubuntu 中搜索某一版本的 glibc 的 gadget 出现如下报错可以尝试换另一个版本的 Ubuntu 。貌似是权限问题,可以以 root 权限重新装一下。

seccomp-tools
用于查看和生成程序沙箱规则。
安装:
1
sudo gem install seccomp-tools
使用:
1
seccomp-tools dump ./pwn
LibcSearcher
通过泄露的 libc 中函数的地址来确定 libc 版本。
1 | git clone https://github.com/lieanu/LibcSearcher.git |
glibc-all-in-one
临时找 glibc 和 ld 或者编译 glibc 。
1 | git clone https://github.com/matrix1001/glibc-all-in-one.git |
更新下载列表:
1 | ➜ glibc-all-in-one ./update_list |
下载 libc ,注意要安装解压工具 zstd ,因为下载脚本中用到了。
1 | sudo apt-get install zstd |
编译 libc
1 | sudo ./build [版本例如2.29] [架构例如 i686 amd64] |
patchelf
安装:
1 | sudo apt install patchelf |
qemu
1 | sudo apt install qemu-user qemu-system |
ELF 文件格式
ELF(Executable and Linkable Format)是一种通用的目标文件 / 可执行文件格式,是 System V ABI 的一部分,目前在多数类 Unix 系统(Linux、*BSD、Solaris 等)上作为标准的二进制格式,用于:
- 可执行文件(executable)
- 可重定位目标文件(object file)
- 共享对象(shared object / shared library)
- 核心转储文件(core dump)
在 ELF/ABI 里的 System V ABI 即 System V Application Binary Interface,这是一个规范文档,最早是在 UNIX System V / SVR4 体系下制定的;
这里的 UNIX System V 是历史上的 UNIX System V 操作系统;
其中 System V Release 4(SVR4) 是一个重要版本:
- 把很多特性(包括 ELF 格式、共享库、System V IPC 等)标准化;
- 影响了后来的很多类 Unix 系统,包括 Solaris、现代 Linux 的很多接口习惯。
今天你经常看到的几个词:
- SysV IPC:System V 风格的进程间通信(
shmget/semget/msgget等);- SysV init:老式的
/etc/init.drc*.d那一套 init 系统;- System V shared libraries:早期 SysV 提出的共享库机制(后发展为 ELF 动态链接)。
这些“SysV”大多就是从那个时代的 UNIX System V 演化来的。
它定义了很多东西“在二进制层面究竟长啥样”:
- ELF 文件格式(头、节、程序头、重定位、动态链接等);
- 调用约定(函数参数怎么压栈、寄存器怎么用);
- 动态链接行为、重定位类型、符号解析规则;
- 等等。
Linux、glibc、GCC、binutils 这些主流工具链,基本都是:
- 在 System V ABI 这套规范的基础上;
- 再加上一些各自的扩展(比如
.gnu.hash、.eh_frame、TLS、CET 等)。所以当我们说:
- “System V 风格 ELF”
- “遵循 System V ABI 的 x86‑64 Linux”
- “System V i386 ABI 规定了 R_386_32 / R_386_PC32 等重定位类型”
指的就是:
这是按 System V ABI 那套规则来玩 ELF 和动态链接的,
而不是别的什么私有格式(比如 Windows 的 PE/COFF,macOS 的 Mach‑O 等)。
ELF 头中的 e_type 字段描述该 ELF 文件的“对象类型”:
ET_REL(1)——可重定位文件(Relocatable file)- 编译器生成的中间目标文件,一般扩展名为 **
.o**。 - 不能直接执行,必须经过链接器处理,生成
ET_EXEC或ET_DYN。 - 静态库
.a并不是一种单独的 ELF 类型,而是一个 ar 归档文件,里面打包了多个ET_REL的 ELF 目标文件。
- 编译器生成的中间目标文件,一般扩展名为 **
ET_EXEC(2)——可执行文件(Executable file)- 传统意义上的“普通可执行程序”,装载基址一般是固定的(非 PIE)。
- 在现代 Linux 上,如果启用 PIE,主程序通常会使用
ET_DYN而不是ET_EXEC。
ET_DYN(3)——共享对象文件(Shared object file)- 最典型的是共享库,扩展名通常是 **
.so**(例如libc.so.6)。 - 同时,现代的 PIE(Position-Independent Executable)主程序 也经常是
ET_DYN:本质上就是“可以当主程序启动的共享对象”。
- 最典型的是共享库,扩展名通常是 **
ET_CORE(4)——核心转储文件(Core file)- 程序崩溃时,内核生成的内存快照,用于调试。
- 包含进程地址空间、寄存器等运行时状态。
除此之外,还有:
ET_NONE:无类型 / 未定义;ET_LOOS~ET_HIOS、ET_LOPROC~ET_HIPROC:保留给特定 OS / CPU 扩展使用。
ELF 规范同时定义了 32 位(ELFCLASS32)和 64 位(ELFCLASS64)两套结构。两者在整体布局上是兼容的:
同样都有:
- ELF 文件头
Elf32_Ehdr/Elf64_Ehdr - 程序头表
Elf32_Phdr/Elf64_Phdr - 节表
Elf32_Shdr/Elf64_Shdr
- ELF 文件头
大部分结构只是:
- 字段宽度不同(32 位地址 / 偏移 VS 64 位地址 / 偏移);
- 个别字段为保证对齐,顺序略有调整(例如
Elf64_Phdr中先是p_type、p_flags,再是 offset / addr 等)。
在 Linux 系统上,这些结构和相关常量通常由 <elf.h> 提供,头文件路径一般在 /usr/include/elf.h 或 C 库的专用 include 目录中。
elf.h 通过 typedef 定义了一组与具体平台无关的基础类型,用来描述 ELF 各种结构体中的字段。不同实现写法略有差别,但主流实现(glibc、Linux 内核、LLVM 等)的定义基本一致:
| 自定义类型 | 含义(语义) | 常见底层类型 | 长度(字节) |
|---|---|---|---|
Elf32_Addr |
32 位地址(虚拟地址) | uint32_t |
4 |
Elf32_Half |
16 位无符号整数 | uint16_t |
2 |
Elf32_Off |
32 位文件偏移 | uint32_t |
4 |
Elf32_Word |
32 位无符号整数 | uint32_t |
4 |
Elf32_Sword |
32 位有符号整数 | int32_t |
4 |
Elf64_Addr |
64 位地址(虚拟地址) | uint64_t |
8 |
Elf64_Half |
16 位无符号整数 | uint16_t |
2 |
Elf64_Off |
64 位文件偏移 | uint64_t |
8 |
Elf64_Word |
32 位无符号整数(仍为 32bit) | uint32_t |
4 |
Elf64_Sword |
32 位有符号整数(仍为 32bit) | int32_t |
4 |
说明:
Word/Sword并不是“跟随地址宽度扩成 64 位”,而是统一定义为 32 位整型;真正的 64 位整型在 ELF 里通常用
Xword/Sxword:
Elf32_Xword/Elf32_Sxword:在 32 位变体里偶尔用到;Elf64_Xword/Elf64_Sxword:64 位 ELF 中大量使用(如某些 size 字段)。
从整体结构上看,一个 ELF 文件大致由以下几部分组成:

ELF 文件头(ELF Header,
Elf*_Ehdr)出现在文件开头,包含:
- 魔数
\x7fELF和一些“识别信息”(位宽、大小端、ABI 等); - 文件类型
e_type、目标架构e_machine、版本e_version; - 程序入口
e_entry; - 程序头表偏移
e_phoff、节表偏移e_shoff; - 各表项大小 / 数量(
e_phentsize、e_phnum、e_shentsize、e_shnum)等。
- 魔数
程序头表(Program Header Table,
Elf*_Phdr,描述“段 Segment”)只有需要被装载执行的文件才真正用到(典型是
ET_EXEC、ET_DYN、ET_CORE);目标文件
ET_REL一般没有程序头表(规范允许有,但常见工具不会生成);每个
Elf*_Phdr描述一个 段(Segment):- 段类型
p_type(如PT_LOAD、PT_DYNAMIC、PT_INTERP等); - 文件偏移
p_offset、内存虚拟地址p_vaddr; - 文件中大小
p_filesz、内存中大小p_memsz; - 读 / 写 / 执行等权限标志
p_flags; - 对齐要求
p_align等。
- 段类型
段是面向“运行时装载”的视图:内核 / 动态链接器根据 Program Header 来决定如何把文件映射到进程的虚拟地址空间。
节表(Section Header Table,
Elf*_Shdr,描述“节 Section”)所有 ELF 文件(包含
ET_REL)都可以有节表,用于链接 / 调试等工具。每个
Elf*_Shdr描述一个 节(Section):- 节名索引
sh_name(指向.shstrtab); - 节类型
sh_type(如SHT_PROGBITS、SHT_SYMTAB、SHT_STRTAB、SHT_NOBITS等); - 标志
sh_flags(可写 / 可执行 / 是否占用内存等); - 文件偏移
sh_offset、大小sh_size; - 对齐
sh_addralign、表项大小sh_entsize(如符号表、重定位表)等。
- 节名索引
段与节的关系:
节(Section):
- 主要服务于 链接器 / 调试器 / 静态分析工具;
- 例如
.text、.data、.bss、.rodata、.symtab、.strtab、.rel.text等; - 一个文件可以有很多细粒度的节,每个节有清晰的类型、用途。
段(Segment):
- 主要服务于 运行时装载(内核、动态链接器);
- 典型的
PT_LOAD段会把若干具有相同权限属性(如R-X、RW-)的节“打包”进同一块连续的虚拟地址区间,以减少映射次数、简化权限设置。 - 段和节之间是 多对多的映射关系,并不是简单“若干属性相同的节合成一个段”,而是由链接脚本和链接器策略决定。
可以通俗地这么理解:
节 = 文件视图,偏重“这块数据是什么”;
段 = 运行时视图,偏重“这块数据如何被映射到内存、有什么权限”。
文件头
每个 ELF 文件开头都有一个 文件头(ELF Header),用于描述整个文件的基本属性和布局信息。无论是:
- 可重定位文件(
.o,ET_REL), - 可执行文件(
ET_EXEC), - 共享对象(
.so,ET_DYN), - 核心转储文件(
ET_CORE),
都必须以同一个 ELF 头结构开头。
以 32 位的 Elf32_Ehdr 为例(64 位的 Elf64_Ehdr 字段完全对应,只是类型宽度不同):
1 |
|
e_ident:魔数和基础属性e_ident是一个长度为 16 字节的数组,用来描述 ELF 文件的“标识信息”。各字节含义如下(用常见的宏名标号):1
2
3
4
5
6
7
8
9
10e_ident[EI_MAG0] = 0x7f;
e_ident[EI_MAG1] = 'E';
e_ident[EI_MAG2] = 'L';
e_ident[EI_MAG3] = 'F';
e_ident[EI_CLASS]; // 32/64 位
e_ident[EI_DATA]; // 字节序
e_ident[EI_VERSION]; // ELF 版本
e_ident[EI_OSABI]; // OS/ABI
e_ident[EI_ABIVERSION]; // ABI 版本
e_ident[EI_PAD..15]; // 填充/保留前 4 字节(
EI_MAG0~`EI_MAG3`) 固定为\x7f 'E' 'L' 'F',用来标识“这是一个 ELF 文件”。第 5 字节:
EI_CLASS表示 ELF 的 位宽类别(注意不是“文件类型”):ELFCLASS32 (1):32 位 ELF;ELFCLASS64 (2):64 位 ELF。
第 6 字节:
EI_DATA表示 字节序:ELFDATA2LSB (1):小端;ELFDATA2MSB (2):大端;- 0 为无效。
第 7 字节:
EI_VERSION表示 ELF 标准版本,目前固定为:EV_CURRENT (1):当前 ELF 规范版本,仅仅是一个版本号,并不是“1.2 版本”之类的概念。
第 8 字节:
EI_OSABI指示目标 OS/ABI,比如:ELFOSABI_SYSV(System V,最常见),- Linux、FreeBSD 等的专有值。
**第 9 字节:
EI_ABIVERSION**:OS/ABI 的版本号,大部分系统中为 0。第 10~15 字节:
EI_PAD及保留:用于填充和保留,一般填 0,部分平台可能用这几字节做扩展。
e_type:文件类型表示 ELF 文件的整体类型,常见取值(宏名以
ET_开头):ET_REL:可重定位文件(.o);ET_EXEC:可执行文件;ET_DYN:共享对象(.so),也包括 PIE 可执行文件;ET_CORE:core dump。
e_machine:目标体系结构表示目标架构 / 指令集,例如:
EM_386、EM_X86_64、EM_ARM、EM_AARCH64等。
不同架构在重定位类型、指令编码、对齐等方面都不相同,动态链接器、调试器等会根据这个字段选择对应的处理逻辑。
e_version:ELF 文件版本一般为:
EV_CURRENT (1)。它与
e_ident[EI_VERSION]一致,都是当前 ELF 版本号,一般不会是其它值。
e_entry:程序入口虚拟地址表示程序开始执行时的 入口虚拟地址:
对 可执行文件 / PIE / 共享对象:
- 指向程序或共享库的入口地址;
- 对可执行文件来说,内核或动态链接器最终会跳到这里,执行运行时初始化后再进入
main。
对 可重定位文件(
ET_REL):- 通常没有入口意义,一般为 0。
e_phoff:程序头表文件偏移表示 程序头表(Program Header Table)在文件中的偏移(字节):
- 对
ET_EXEC/ET_DYN/ET_CORE:通常非 0,内核 / 动态链接器加载时必须用到; - 对
ET_REL:一般为 0(不需要程序头表,但规范允许存在)。
若
e_phoff == 0,通常表示“本文件没有程序头表”。- 对
e_shoff:节头表文件偏移表示 节头表(Section Header Table)在文件中的偏移(字节):
- 链接器、调试器通过它来定位
.text、.data等各节的元信息; - 对某些被完全 strip 的可执行文件 / 共享库,
e_shoff可能为 0(没有节表),程序依然可以正常执行,只是调试 / 链接信息丢失。
- 链接器、调试器通过它来定位
e_flags:处理器特定标志这是一个与架构相关的标志字段:
- 对 x86 / x86‑64 等架构通常为 0;
- 对 ARM、MIPS 等架构,可能编码 ABI、指令集模式等信息。
其具体意义需要参考对应架构的 ABI 文档。
e_ehsize:ELF 头大小表示 ELF 文件头自身的大小(字节数):
- 对 32 位 ELF,一般为
sizeof(Elf32_Ehdr),典型值 52; - 对 64 位 ELF,一般为
sizeof(Elf64_Ehdr),典型值 64。
解析 ELF 时可以用该字段来校验读到的头部是否完整。
- 对 32 位 ELF,一般为
e_phentsize/e_phnum:程序头表项大小与数量e_phentsize:程序头表中 每个表项(Elf*_Phdr)的大小;e_phnum:程序头表中 表项数量。
当
e_phnum == 0时,表示本文件中没有程序头表(例如纯ET_REL文件或某些特殊构造)。
e_shentsize/e_shnum:节头表项大小与数量e_shentsize:节头表中 每个表项(Elf*_Shdr)的大小;e_shnum:节头表中 表项数量。
当
e_shnum == 0时,通常意味着文件中没有节表(例如被完全 strip 且不再需要调试 / 链接用途的二进制)。
e_shstrndx:节名字符串表索引e_shstrndx指明:在节头表中,哪一个节(按
Elf*_Shdr索引)是 节头字符串表(Section Header String Table,一般名为.shstrtab)。.shstrtab中保存了所有“节名”的字符串;- 每个
Elf*_Shdr::sh_name字段是相对于.shstrtab的偏移; - 若
e_shstrndx == SHN_UNDEF (0),通常表示没有节名字符串表(少见,多见于特殊或混淆过的 ELF)。
程序头表
在 ELF 中,有两套“描述结构”:
- 节表(Section Header Table):描述的是 节(Section),主要给链接器、调试器用。
- 程序头表(Program Header Table):描述的是 段(Segment),主要给操作系统装载器 / 动态链接器用。
一般来说:
- 可执行文件(
ET_EXEC):有程序头表; - 共享对象(
ET_DYN,共享库 / PIE):有程序头表; - 可重定位目标文件(
ET_REL):通常没有程序头表,只需要节表即可(也可以有,但实际工具链基本不会这么干)。
程序头表描述的是装载相关的“段”,而目标文件不直接被操作系统装载执行,所以通常不需要程序头表。
程序头表是一个由 Elf*_Phdr 结构体构成的数组,每个 Phdr 描述一个 段(Segment),而不是“每个节”。
段是面向“内存装载”的视图:
OS 根据程序头表决定:- 从文件的哪个偏移 (
p_offset) 读多少字节 (p_filesz) - 把它们映射到内存中的哪个虚拟地址 (
p_vaddr),映射多大 (p_memsz) - 映射的权限(读 / 写 / 执行:
p_flags)
- 从文件的哪个偏移 (
一个段可以覆盖多个节;多个属性相同的节会被合并进同一个
PT_LOAD段里。
以 32 位为例(64 位只是字段宽度不同)Elf32_Phdr 结构如下:
1 | /* Program segment header. */ |
各字段含义:
p_type:段类型指定该条目表示什么类型的段,常见值(省略很多):
PT_NULL:无效条目,忽略;PT_LOAD:可装载段,真正会映射到进程虚拟地址空间(代码 / 数据等都在这里);PT_DYNAMIC:动态链接信息所在的段,对应.dynamic;PT_INTERP:解释器(通常是动态链接器)路径所在段,对应.interp;PT_NOTE:NOTE信息;PT_GNU_STACK等:GNU 扩展,用于指定栈是否可执行。
“可执行段、数据段”这类说法其实是由
PT_LOAD+p_flags(读写执行)组合出来的,而不是p_type本身区分“代码段 / 数据段”。p_offset:文件偏移段在 文件中的起始偏移(字节)。装载器从这个位置开始读数据。
p_vaddr:虚拟地址段在 进程虚拟地址空间中的起始地址。
对于PT_LOAD段,必须是页对齐的,且会参与实际的内存映射。
对于某些非装载段(如PT_NOTE),这个字段的解释依 ABI 而定,可能为 0 或未使用。p_paddr:物理地址段在物理内存中的地址。
- 在大多数通用操作系统(Linux 等)中,进程只关心虚拟地址,这个字段通常被忽略或与
p_vaddr保持一致,更多是给某些裸机 / 特殊系统预留的。 - 所以简单记:在普通用户空间程序里,可以当作保留字段看待。
- 在大多数通用操作系统(Linux 等)中,进程只关心虚拟地址,这个字段通常被忽略或与
p_filesz:文件中大小段在文件中占据的字节数。
p_memsz:内存中大小段映射到内存时占据的字节数。
常见关系:
p_memsz >= p_filesz- 对于
.bss这种“未初始化数据”,相应部分不会写入文件,只在内存中以 0 填充; - 这时
p_filesz小于p_memsz,多出来的部分由内核(或运行时)做清零。
- 对于
p_flags:段标志常用为位组合:
PF_X:可执行PF_W:可写PF_R:可读
OS 会据此设置内存页的权限。
p_align:对齐要求段在文件和内存中的对齐约束:
若
p_align > 1,则通常需要满足:p_vaddr % p_align == p_offset % p_align
对于
PT_LOAD段,p_align一般是 页大小(如 0x1000),确保段起始地址为页对齐。若
p_align为 0 或 1,表示没有特殊对齐要求。
节表
ELF 文件中使用一组 Elf*_Shdr 结构体来描述每一个节,这些结构体顺序排在一起,构成 节表(Section Header Table):
- 每个表项大小固定(
e_shentsize),类型为Elf32_Shdr或Elf64_Shdr; - 表项个数由 ELF 头里的
e_shnum指定; - 整个节表在文件中的位置由
e_shoff给出。
段(Segment) vs 节(Section)
节(Section)
是文件级的逻辑组织单位,用来按“用途”划分内容:
- 代码:
.text- 已初始化数据:
.data- 未初始化数据:
.bss(SHT_NOBITS)- 只读数据:
.rodata- 符号表:
.symtab- 字符串表:
.strtab/.dynstr- ……
每个节在节表里对应一个
Elf*_Shdr表项,给出它在文件中的偏移、大小、属性等。链接器 / 调试器主要看“节”。
段(Segment)
- 是内存装载视图,由 Program Header(
Elf*_Phdr,类型PT_LOAD/PT_DYNAMIC/PT_INTERP等)描述;- 一个段通常对应进程虚拟地址空间中的一个连续区间(比如“这块内存可读+可执行,用来放代码”和“这块内存可读+可写,用来放数据”);
- 一个 PT_LOAD 段内部可以包含多个 section(例如
.text+.rodata合在一个只读+可执行段里)。- 操作系统装载器只看“段”(Program Header),可以完全不理会节表。
链接器会把属性相同的节(比如都只读+可执行的
.text/.rodata)打包到同一个PT_LOAD段中;装载时,内核只根据“段”来把文件映射进内存,而不关心“节”的细节。
ELF 使用一个由 Elf*_Shdr 组成的数组来描述所有 节(section),每个表项大小固定,但数组长度(节个数)不固定,由 ELF 头决定。
以 32 位为例(64 位只是字段宽度不同)
Elf32_Shdr结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* Section header. */
typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;各字段含义:
sh_name:节名索引- 表示节名在“节名字符串表”(
.shstrtab)中的索引。 .shstrtab是一个专门用来存放“节名字符串”的节,它本身在节头表中的索引由 ELF 头的e_shstrndx给出。- 因此
sh_name指向的是.shstrtab,不是.strtab/.dynstr这些普通字符串表。
- 表示节名在“节名字符串表”(
sh_type:节类型描述该节的类型,从而决定这节的用途和解释方式。
常见取值(只列常用的):
SHT_NULL (0):无效节(占位用)。SHT_PROGBITS (1):程序自定义内容(代码、常量等),例如.text、.rodata、.data通常都是这个类型。SHT_SYMTAB (2):静态符号表,例如.symtab。SHT_STRTAB (3):字符串表,例如.strtab、.dynstr、.shstrtab。SHT_RELA (4)/SHT_REL (9):重定位表(分别为带 / 不带显式 addend 的形式)。SHT_NOBITS (8):不在文件中占空间的节,例如.bss。- ……
注意:**“代码段 / 数据段”是节的用途,不是不同的
sh_type**,代码和数据一般都属于SHT_PROGBITS。
sh_flags:节标志描述该节在内存中的属性,常见标志:
SHF_WRITE:节在内存中可写。SHF_ALLOC:装载时会被映射到进程地址空间。SHF_EXECINSTR:节中包含可执行指令。- ……
链接器 / 装载器会据此决定该节应放入什么样的
PT_LOAD段,以及映射时的页权限(r/w/x)。
sh_addr:虚拟地址- 表示该节在内存中的虚拟地址。
- 对 可重定位文件(
ET_REL):一般为 0(尚未分配最终虚拟地址)。 - 对 可执行文件(
ET_EXEC)和共享对象(ET_DYN) 中带SHF_ALLOC的节:该字段表示此节在进程地址空间中的位置(通常是相对装载基址的偏移)。 - 总结:只对带
SHF_ALLOC的节、且在已定址的 ELF(ET_EXEC/ET_DYN)中有实际意义。
sh_offset:文件偏移表示该节在 ELF 文件中的起始偏移(字节)。
对绝大多数节,这就是节内容在文件里的位置。
对
SHT_NOBITS(例如.bss):- 按规范
sh_offset仍然有定义——表示“如果这节在文件中有数据,应该放在这里”; - 但这种节在文件中不占空间,loader 只会根据
sh_type == SHT_NOBITS和sh_size在内存中划出一块区域并清零,而不会从文件这个位置读取。
- 按规范
sh_size:节大小- 表示该节的大小(字节数)。
- 对
SHT_NOBITS:表示这块在内存中需要保留的大小(虽然文件中没有对应数据)。
sh_link:链接信息含义依
sh_type不同而不同,一般用来“指向另一个相关的节”:- 对
SHT_SYMTAB/SHT_DYNSYM:sh_link通常是该符号表所使用的字符串表(.strtab/.dynstr)在节头表中的索引。 - 对重定位节(
SHT_REL/SHT_RELA):sh_link通常是所引用的符号表节的索引。 - 其它类型也有各自约定。
- 对
简单理解:“关联到哪个节”,具体要看节类型的说明。
sh_info:附加信息同样是与
sh_type相关的附加字段:- 对
SHT_SYMTAB/SHT_DYNSYM:通常表示本地符号个数(STB_LOCAL的符号数量)。 - 对重定位节:通常表示“本节要重定位的目标节”的索引。
- 其它类型用法依 ABI 约定。
- 对
可以简单记为:“额外信息字段,其含义随节类型而变”。
sh_addralign:地址对齐约束描述该节在内存中的对齐要求:
若
sh_addralign == 0或sh_addralign == 1:表示没有特别的对齐要求,可认为是字节对齐。否则
sh_addralign一般是 2 的幂,并要求:1
sh_addr % sh_addralign == 0
sh_entsize:表项大小若该节存放的是由定长表项组成的表(例如符号表、重定位表),则
sh_entsize表示每个表项的大小(字节数):- 对
.symtab/.dynsym:通常是sizeof(Elf32_Sym)/sizeof(Elf64_Sym)。 - 对
.rel.*/.rela.*:通常是sizeof(Elf32_Rel)/Elf32_Rela等。
- 对
若
sh_entsize == 0:表示该节不是“定长表项数组”,例如.text、.rodata这类普通数据区域。
ELF 中常见的节如下:
.text
代码节,存放程序的机器指令,通常SHT_PROGBITS+SHF_ALLOC | SHF_EXECINSTR。.rodata
只读数据节,存放字符串常量、常量表等,通常SHT_PROGBITS+SHF_ALLOC(不带SHF_WRITE)。.data
已初始化的可写全局 / 静态变量,通常SHT_PROGBITS+SHF_ALLOC | SHF_WRITE。.bss
未初始化的全局 / 静态变量,SHT_NOBITS,带SHF_ALLOC | SHF_WRITE:- 在文件中不占实际数据空间(只有节头),
- 装载时在内存中分配
sh_size字节并清零。
.symtab
静态符号表,SHT_SYMTAB,供链接器 / 调试器使用,可能在 strip 后被移除。.strtab
字符串表,SHT_STRTAB,配合.symtab存符号名等字符串。.rel.text/.rela.text
代码重定位信息,分别是SHT_REL/SHT_RELA类型,链接时用来修正.text内的地址引用。.rel.data/.rela.data
数据重定位信息,用于修正.data等数据节中的地址引用。.dynamic
动态节,SHT_DYNAMIC,内部是Elf*_Dyn数组,描述动态链接所需的信息:- 动态符号表、字符串表、重定位表的位置和大小;
- 依赖的共享库名(
DT_NEEDED)所在的字符串表索引; - 初始化/终止函数地址等。
本身不是重定位表或符号表,而是这些表的“目录”。
.note.*
注释 / 说明 / 元数据节,SHT_NOTE:- 常见如
.note.ABI-tag、.note.gnu.build-id,存放 ABI 信息、build-id 等; - 不等同于 DWARF 调试节(那些通常是
.debug_*)。
- 常见如
字符串表
在 ELF 文件里会出现大量字符串,例如:
- 段名(section name)
- 符号名(函数名、变量名)
- 动态链接相关的各种名字
由于字符串长度不定,如果在每个需要名字的结构里都直接放一个“定长字符串字段”,会非常浪费空间,也不灵活。
ELF 的做法是:把所有字符串集中放到一个“字符串表”(String Table)里,然后在各个结构中用“偏移量”来引用字符串。
字符串表本质上就是一段连续的字节数组。
某个字段(比如
sh_name、st_name)存的不是字符串本身,而是:从该字符串表起始处到目标字符串开头的 字节偏移(index / offset)。
这样,ELF 内部引用字符串时只要给出一个整数偏移即可,不需要关心字符串实际长度。
在 ELF 中,字符串表以 节(section) 的形式出现,节类型为 SHT_STRTAB。常见的名字有:
.shstrtab—— Section Header String Table- “段表字符串表”:专门存放 段表(section header table)用到的字符串。
- 最典型的就是段名,供
ElfXX_Shdr::sh_name字段引用。
.strtab—— String Table- 一般用作 普通符号表
.symtab的名字字符串表,保存各种符号名(函数名、全局变量名等)。
- 一般用作 普通符号表
.dynstr—— Dynamic String Table- 供
.dynsym(动态符号表)、.dynamic等动态链接相关结构使用,保存运行时需要的那些字符串。
- 供
说明:在简单的介绍里,常会只提
.strtab和.shstrtab两个表来讲概念,这没有问题。但真实 ELF 里还经常能看到.dynstr这样的动态字符串表。
常见的“通过偏移引用字符串”的例子有:
段表条目中的
sh_name字段类型:
uint32_t含义:这是相对于
.shstrtab开头的字节偏移。动态装载器/分析工具会:
- 找到段表字符串表
.shstrtab - 从偏移
sh_name开始,读取一个以'\0'结尾的字符串,这就是该 section 的名字。
- 找到段表字符串表
符号表条目中的
st_name字段(.symtab/.dynsym)- 类型:
uint32_t - 含义:这是相对于对应字符串表 (
.strtab或.dynstr) 开头的字节偏移。 - 通过这个偏移就能拿到符号名。
- 类型:
你可以把字符串表理解成一个字符串池,而 sh_name / st_name 这些字段就是“指向池里面某个字符串的偏移指针”。
ELF 字符串表中的字符串是以 \x00 结尾的 C 风格字符串,字符串之间紧挨着存放。
关键点:
每个字符串是:
- 若干个非零字节
- 后面跟一个
'\0'(即\x00)作为结尾
整个字符串表的第 0 个字节 被规定为
'\0':- 这就构成了一个“空字符串”,偏移为 0。
- 当某些字段(比如
sh_name或st_name)为 0 时,就表示“没有名字”或“名字为空”。
相邻字符串之间 只需要结尾处的那个
\x00来做分隔,不会在“每个字符串的开头再填一个\x00”。
调用约定
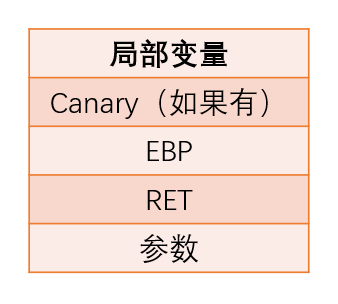
栈结构
注意
canary 不一定与 ebp 相邻,因为有些函数会先将一些寄存器保存到栈中。canary 实际位置以调试为准。
函数调用过程
32位为例:
函数参数传递
注意:通常 linux 下的程序的函数调用都是外平栈的。
32 位程序
普通函数
Linux 使用 cdecl 调用约定,所有参数 从右到左 压入栈中。由 调用者(caller) 负责清理栈上的参数。使用 EAX 返回函数值。
系统调用
在 32 位 Linux(x86 架构)中,用户态通过 int 0x80 进入内核执行系统调用。为了提高兼容性,Linux 系统主要采用 int 0x80,而不是 sysenter,因为后者需要硬件支持和额外的返回跳板机制。
系统调用时,调用号和参数都通过寄存器传递,具体分配如下:
EAX寄存器用于存放系统调用号(syscall number)。EBX、ECX、EDX、ESI、EDI、EBP依次用于传递系统调用的第 1 到第 6 个参数。
系统调用返回时,结果会存放在 EAX 中。如果调用成功,EAX 中为返回值;如果失败,则 EAX 为负值(对应负的 errno 编号)。
64位程序
普通函数
在 64 位 Linux(x86_64 架构)中,普通函数调用遵循 System V AMD64 ABI 调用约定,这是当前 Linux 平台上 C/C++ 等语言的标准调用方式。
函数参数通过寄存器优先传递,具体为:
RDI、RSI、RDX、RCX、R8、R9依次用于传递前 6 个参数。- 超过 6 个参数的部分,从右到左压入栈中。
函数返回值通过 RAX 返回,若返回值过大或为结构体,可能使用多个寄存器(必要时用 RDX:RAX 返回 128bit)或通过内存返回。
在寄存器使用上,调用者负责保存 RAX、RCX、RDX、RDI、RSI、R8~R11 等 caller-saved 寄存器;而 RBX、RBP、R12~R15 等 callee-saved 寄存器由被调用函数保存。
函数调用前,要求栈地址必须对齐到 16 字节,否则在使用某些 SSE 指令时会触发崩溃。
系统调用
在 64 位 Linux(x86_64 架构)中,用户态通过 syscall 指令进入内核执行系统调用。相比 32 位的 int 0x80,syscall 是专为 64 位架构设计的系统调用指令,执行效率更高,也是当前主流的调用方式。
系统调用时,调用号和参数都通过寄存器传递,具体分配如下:
RAX寄存器用于存放系统调用号(syscall number)。RDI、RSI、RDX、R10、R8、R9依次用于传递系统调用的第 1 到第 6 个参数。
注意
第 4 个参数使用 R10 而不是 RCX,因为 RCX 在执行 syscall 时会被硬件破坏(用作返回地址保存)。
系统调用返回时,结果会存放在 RAX 中。如果调用成功,RAX 中为返回值;如果失败,则 RAX 为负值(对应负的 errno 编号)。
系统调用号
32 位
1 |
64 位
1 |
程序编译过程
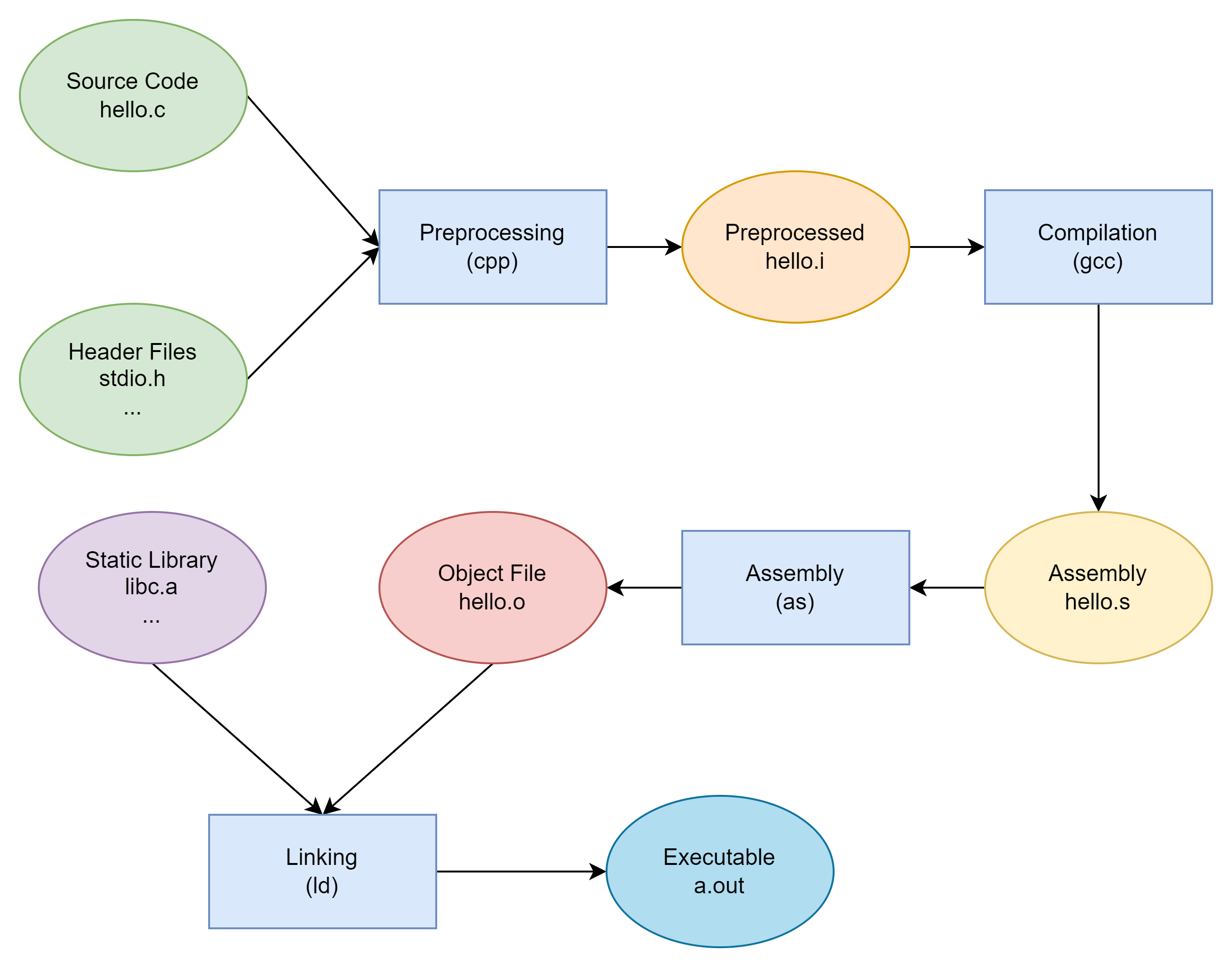
从源码到最终 ELF 可执行文件(或共享库),通常会经历几个主要阶段:
源代码(
.c/.cpp)
➜ 预处理(生成.i/.ii)
➜ 编译(生成汇编.s)
➜ 汇编(生成目标文件.o)
➜ 链接(生成 ELF 可执行文件 / 共享库)
从源文件编译链接形成 ELF 文件的过程如下图所示:
预处理(Preprocessing)
预处理阶段由预处理器(通常是 GCC 内部的 cpp 前端)完成,把源文件和头文件“拼装 + 展开”成一个纯文本的中间文件:
C 源文件:
- 源文件扩展名:
.c - 预处理后扩展名:
.i
- 源文件扩展名:
C++ 源文件:
- 源文件扩展名:
.cpp/.cxx等 - 预处理后扩展名:
.ii
- 源文件扩展名:
典型命令(-E 表示“只做预处理,不继续编译”):
1 | gcc -E hello.c -o hello.i |
或者直接调用预处理器:
1 | cpp hello.c > hello.i |
预处理阶段主要处理所有以 # 开头的预处理指令,常见规则包括:
展开和移除宏定义
- 展开所有通过
#define定义的宏; - 源文件里的
#define本身不会出现在.i中(系统头里的一些实现细节可能因选项不同略有差异)。
- 展开所有通过
处理条件编译指令
- 如
#if/#ifdef/#elif/#else/#endif; - 根据条件选择性地保留或丢弃代码块。
- 如
展开
#include- 将被包含的头文件内容“内联”到当前文件中;
- 这个过程是递归的:包含的文件里还可以继续
#include其他文件。
删除注释
- 删除所有
//和/* ... */注释(变成纯代码文本)。
- 删除所有
插入行号和文件名标记
生成类似下面这样的行标记:
1
# 2 "hello.c" 2
这些用于:
- 编译器在报错/告警时能正确显示“原始源文件 + 行号”;
- 生成调试信息时记录源码位置。
保留必要的
#pragma#pragma指令通常会被保留下来,由后续编译阶段处理。
预处理之后得到的 .i / .ii 文件本质上还是 C/C++ 源代码,只是:
- 所有宏都已经展开;
- 所有
#include的头文件都已经展开进来; - 不再包含一般的预处理指令(除了行标记和部分
#pragma)。
编译(Compilation)
编译阶段的任务是:把预处理后的源代码翻译成目标机器的汇编代码。
编译器在这一阶段会进行:
- 词法分析(Lexical Analysis):把字符流切分成 token;
- 语法分析(Parsing):检查语法是否合法,构建语法树;
- 语义分析(Semantic Analysis):类型检查、作用域解析、常量折叠等;
- 中间表示(IR)生成与优化:如常量传播、死代码删除、循环优化等;
- 目标相关优化:指令选择、寄存器分配等;
- 输出汇编代码(
.s文件)。
常见命令示例(从预处理后的 .i 出发):
1 | gcc -S hello.i -o hello.s |
一般更常用的是直接从 .c 开始,让 GCC 自动完成“预处理 + 编译”两步:
1 | gcc -S hello.c -o hello.s |
此时生成的 hello.s 是与平台/架构相关的 汇编代码。
汇编(Assembly)
汇编阶段由汇编器(如 GNU as,但通常通过 gcc 间接调用)完成,把 .s 汇编代码翻译成机器码,生成 目标文件(Object File,.o)。
每条汇编指令大多对应一条机器指令(也会有伪指令、宏指令等间接映射的情况);
相比编译器,汇编器的工作相对简单:
- 不再做高级语言的语法/语义分析;
- 主要负责解析汇编伪指令、符号、重定位信息、节布局等;
- 将其组织成符合目标平台 ABI 的 ELF 目标文件。
可以直接调用汇编器:
1 | as hello.s -o hello.o |
更常见的是用 gcc 一步从 C 源码生成 .o,让它在内部自动完成“预处理 + 编译 + 汇编”:
1 | gcc -c hello.c -o hello.o |
-c 的含义是:只生成目标文件,不进行链接。
得到的 hello.o 一般是 ELF 格式的 ET_REL 文件,包含:
- 机器指令和数据;
- 符号表、重定位表等链接所需的信息。
链接(Linking)
“编译过程中的链接阶段” = 由 ld 完成的,把一堆 .o 和库文件合成一个 ELF 的那一步,它是所有程序(无论静态还是动态链接)都会经历的统一阶段。
这一阶段对应如下命令:
1 | gcc main.o foo.o -o prog # gcc 在背后帮你调用 ld |
输入:
一个或多个 目标文件:
main.o、foo.o…
内部是 ELF
ET_REL,包含:
- 各种节:
.text、.data、.bss等- 符号表
.symtab/ 字符串表.strtab- 重定位表
.rel.text、.rel.data/.rela.*若干 库文件:
静态库:
libxxx.a
- 其实是很多
.o的打包(ar 格式),链接器会按需从里面挑成员出来用共享库:
libxxx.so
- ELF
ET_DYN文件启动文件 / 运行时:
crt1.o、crti.o、crtn.o等 C 运行库的启动代码libgcc.a等编译器运行时支持库输出:
- 可执行文件:
prog
- 传统非 PIE:
ET_EXEC- PIE:
ET_DYN,但带入口、可直接运行- 或者 共享库:
libxxx.so(ELFET_DYN)
静态 / 动态程序的区别,只在于链接器把多少工作留到运行时去做。
站在“编译期链接器”的角度:
静态链接程序(
-static)
- 把用到的静态库
.a中的函数 / 变量实现代码都拷贝进最终可执行文件;- 尽量在链接阶段把所有符号地址定死;
- 最终 ELF 通常没有
PT_INTERP,运行时不需要动态链接器参与;- GOT/PLT 也可以存在,但只在程序内部跳,不依赖外部
.so。动态链接程序(默认)
自己的
.o+ 启动文件依然正常合并、重定位;对共享库
.so:
- 不复制代码,只登记依赖(
DT_NEEDED);- 建好
.dynsym/.dynstr/.rela.*/.plt/.got等结构;- 留下一部分重定位条目由动态链接器在运行时处理。
最终 ELF 一定有
PT_INTERP(指定动态链接器)。所以,编译阶段的“链接”总是存在,无论你生成的是静态程序还是动态程序,只是:
- 静态程序:绝大部分链接工作在这一阶段一次性完成;
- 动态程序:这一阶段先完成一部分,剩下交给运行时的动态链接器继续做。
ELF 相关结构
在 可重定位目标文件(ET_REL,即 .o) 中,链接器主要依赖以下信息完成“静态链接”:
符号表:
.symtab(SHT_SYMTAB,元素类型Elf*_Sym)字符串表:
.strtab(存放符号名等)重定位表:
- 代码相关:
.rel.text/.rela.text - 数据相关:
.rel.data/.rela.data
- 代码相关:
以及各种属性节(
.text/.data/.bss等)
静态链接时使用的重定位节(.rel.text / .rela.text、.rel.data / .rela.data 等)只存在于 ET_REL 这样的中间目标文件中。
当链接器把多个 .o 合成最终的 可执行文件(ET_EXEC) 或 共享对象 / PIE(ET_DYN) 时,会:
读取这些重定位条目;
把对应位置的指令 / 数据修正好;
通常会把这些“静态重定位节”删掉,所以在最终 ELF 里一般看不到
.rel.text/.rel.data之类。当链接器把一堆
.o链起来之后,静态链接这轮其实已经结束了,从链接器的角度:- 符号都已经解析好了;
- 该重定位的都打好补丁了;
- 那么理论上,“给静态链接用的那些
.symtab/.strtab/.rel.*也可以不用保留了”。
所以从 纯“执行程序”角度 看:
- **运行时不需要
.symtab/.strtab**(动态链接用的是.dynsym/.dynstr,那是另一套); - 也不需要
.rel.text/.rel.data(静态链接用完就扔了); - 留它们只是方便人类和工具(调试、反汇编、分析等)。
关键点:链接器的默认行为是“生成未 strip 的二进制”——方便你:
- 用
gdb调试; - 用
nm/objdump看符号名; - 在崩溃 backtrace 中能打印出函数名,而不仅是地址。
而且注意:
.symtab就算没有-g,通常也会存在(只是符号信息没那么丰富);-g控制的是生成.debug_*等 DWARF 调试信息节(.debug_info、.debug_line、.debug_abbrev等),而不直接控制.symtab是否出现。
换句话说:
.symtab/.strtab= 符号表 + 名字表,链接器必用,在最终 ELF 里保留与否是“方便人”的选择;-g= “生成详细调试信息(DWARF)”,主要体现在.debug_*这些节上。
真正控制
.symtab/.strtab要不要留的,是strip或链接器选项,比如:strip prog/strip --strip-all prog- 会干掉大部分符号信息(包括
.symtab、.strtab、.debug_*等);
- 会干掉大部分符号信息(包括
strip --strip-debug prog- 只删调试节
.debug_*,通常会保留必要的符号(比如.dynsym),具体行为看实现;
- 只删调试节
链接时用
-Wl,--strip-all/-s:- 直接让 ld 在生成时就去掉符号。
这就是为什么:
- 你看到有些 pwn 题附件有函数名、有
.symtab(没 strip 或只 strip 了调试信息); - 有些则啥名都没了,只剩下
.dynsym或极少量符号(被 strip 过)。
与之对应,最终的可执行文件 / 共享对象里还会保留一套“动态重定位信息”(例如 .rela.dyn、.rela.plt),是给 动态链接器在运行时 用的,主要用于:
- 根据实际装载地址(ASLR / PIE)修正 GOT、静态指针等(
R_*_RELATIVE); - 修正导入函数 / 变量(
R_*_JUMP_SLOT、R_*_GLOB_DAT等)。
符号表(.symtab)
在 ELF 文件中,静态符号表通常是一个名为 .symtab 的节:
- 节类型:
SHT_SYMTAB - 元素类型:
Elf32_Sym/Elf64_Sym数组
以 32 位为例:
1 | /* Symbol table entry. */ |
各字段含义:
st_name:符号名索引- 指向某个 字符串表节(通常是
.strtab)中的偏移; - 字符串表的节索引(section index)由符号表节头的
sh_link指定。
- 指向某个 字符串表节(通常是
st_value:符号值在 可重定位文件(
ET_REL) 中:如果符号是定义在某个节里的(且
st_shndx不是特殊值,例如既不是SHN_UNDEF也不是SHN_COMMON),
则st_value表示 相对于该节起始地址的偏移;如果
st_shndx == SHN_COMMON(所谓“COMMON 块”/暂定定义),
则:st_value表示该符号所需的 对齐;st_size表示所需空间大小。
链接器最终会把这些符号分配到
.bss等处。
在 可执行文件 / 共享对象(
ET_EXEC/ET_DYN) 中:- 对带
STB_GLOBAL/STB_WEAK等可见性符号,st_value一般表示符号的 虚拟地址(或相对装载基址的偏移)。
- 对带
st_size:符号大小- 对函数符号:通常是函数机器码的长度;
- 对对象符号:是该对象占用的字节数;
- 若为 0:表示大小为 0 或未知(链接器 / 调试器会根据实际上下文处理)。
st_info:类型 + 绑定这是一个打包字段:
- 高 4 位:绑定(binding),
STB_LOCAL/STB_GLOBAL/STB_WEAK等; - 低 4 位:类型(type),
STT_NOTYPE/STT_OBJECT/STT_FUNC/STT_SECTION等。
- 高 4 位:绑定(binding),
取值一般通过宏:
ELF32_ST_BIND(st_info)得到绑定;ELF32_ST_TYPE(st_info)得到类型;ELF32_ST_INFO(bind, type)组装。
st_other:可见性等信息- 低 2 位通常表示 符号可见性:
STV_DEFAULT/STV_HIDDEN/STV_PROTECTED等; - 其它位保留,一般为 0。
- 低 2 位通常表示 符号可见性:
st_shndx:所在节索引 / 特殊标记一般情况:
st_shndx为某个有效节号,表示符号定义于该节;
特殊情况(部分):
SHN_UNDEF:未定义符号(当前文件中只引用、未定义),需要在链接时从其他目标文件 / 库中解析。SHN_ABS:绝对符号,其值不随重定位变化(如某些常量)。SHN_COMMON:COMMON 符号(见上:st_value表示对齐,st_size为空间大小)。
重定位表(.rel.* / .rela.*)
在 静态链接阶段,链接器通过重定位表知道“哪些位置需要根据符号的最终地址进行修正”。
常见的“静态重定位节”有:
.rel.text/.rela.text:对.text代码节中的重定位;.rel.data/.rela.data:对.data等数据节中的重定位。
.rel.*和.rela.*都是“重定位节”,区别在于:**.rel.*用的是Elf*_Rel,没有显式 addend;**
.rel.*:节类型是 **SHT_REL**,元素结构是Elf32_Rel/Elf64_Rel:
2
3
4
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
} Elf32_Rel;没有
r_addend字段。
.rela.*:节类型是 **SHT_RELA**,元素结构是Elf32_Rela/Elf64_Rela:
2
3
4
5
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
Elf32_Sword r_addend; /* Addend */
} Elf32_Rela;多了一个
r_addend字段。节名的约定通常是:
- 用
SHT_REL的节叫.rel.xxx- 用
SHT_RELA的节叫.rela.xxx名字本身没有魔法,只是惯例;真正的区别在
sh_type和表项结构体。所有 ELF 重定位的计算本质都是类似:
新值 = 符号值
S+ addendA(再根据重定位类型决定是不是还要加P等)区别只在于 addend
A从哪儿来:
Elf*_Rel里没有r_addend字段;addend 存在被重定位的位置本身:
对
ET_REL:编译器/汇编器在生成.o时,把一个“初始值”写到r_offset对应的位置;链接器 / 动态链接器在做重定位时:
- 先读出当前位置原来的内容,作为 addend
A;- 用
S、A、重定位类型算出新值;- 再把新值写回这个位置。
可以理解为:“addend 嵌在代码/数据里”。
Elf*_Rela里有显式的r_addend;**addend 不再从内存中读,而是直接用表项里的r_addend**:
- 计算时直接用
A = r_addend,然后根据类型算出新值写到r_offset位置;- 重定位前,
r_offset对应地址里的内容对计算不重要(往往是 0)。可以理解为:“addend 单独存在重定位表里”。
以 32 位 REL 为例(不带 addend):
1 | /* Relocation table entry without addend (in section of type SHT_REL). */ |
各字段含义:
r_offset:待修正位置对于 可重定位文件(
ET_REL):r_offset表示“需要重定位的位置相对于所属节起始的偏移”;- 哪个节要被重定位,是通过重定位节头的
sh_info字段指向的。
对于最终的 可执行文件 / 共享对象中的动态重定位表(如
.rela.dyn/.rela.plt):r_offset一般是“待修正位置的虚拟地址”或者装载基址上的偏移;这时是动态链接器在运行时根据它进行修正。
r_info:符号索引 + 重定位类型这是一个打包字段,包含:
- 符号索引(指向某个符号表条目,一般是
.symtab/.dynsym); - 重定位类型(
R_*);
- 符号索引(指向某个符号表条目,一般是
在 32 位 System V ABI 下,通常约定:
低若干位为重定位类型;
高若干位为符号索引;
glibc 提供宏:
ELF32_R_SYM(r_info):取符号索引;ELF32_R_TYPE(r_info):取重定位类型;ELF32_R_INFO(sym, type):组合。
对
RELA形式(Elf32_Rela/Elf64_Rela)还会多一个r_addend字段,表示显式的加数,用法与具体重定位类型相关。
链接过程
收集 & 合并节
每个
.o里都有自己的.text/.data/.rodata/.bss等节;链接器根据链接脚本(默认或自定义)的规则,把多个目标文件里的同类节合并在一起,例如:
- 所有
.text→ 合成一个大的.text; - 所有
.data→ 合成一个大的.data; - 所有
.bss→ 合成一个大的.bss;
- 所有
同时决定它们在最终 ELF 中的文件布局顺序、对齐方式等。
符号解析(Symbol Resolution)
核心问题就是一句话:
“这个符号到底是哪个
.o/ 库里定义的?它对应哪一段代码或哪个变量?”
链接器会:
扫描所有
.o和库文件,读取它们的.symtab/.strtab:- 找到每个“符号名 → 定义位置”的对应关系;
- 本地符号(
STB_LOCAL)只在各自目标文件内部使用,不参与全局解析; - 全局 / 弱符号(
STB_GLOBAL/STB_WEAK)参与跨文件可见的解析。
处理未定义符号(
st_shndx == SHN_UNDEF):- 在当前
.o里只被引用,没有定义; - 链接器会在其它
.o或库中寻找相应的定义; - 找不到就报“未定义引用”。
- 在当前
对 静态库
.a的特殊处理:.a是很多.o的集合,链接器不会一次性把所有成员都拉进来;- 只有当某个未定义符号需要时,才按需从
.a中挑出某个.o加入链接; - 没有被用到的成员
.o不会被加入最终文件。
冲突检查:
- 同名全局符号在多个文件中均为强符号定义:报多重定义错误;
- 弱符号(
STB_WEAK)与强符号之间有一套优先级规则:通常是“强覆盖弱”。
这一步的结果是:
对于每一个“需要被引用的符号”,链接器都知道它:
- 在最终合并后的哪个节里;
- 偏移多少;
- 大小是多少。
地址分配 & 静态重定位(Relocation)
在有了“全局布局 + 符号解析结果”之后,链接器开始做“修地址”的工作。
地址分配(Assign Addresses) :为合并后的
.text/.data/.bss等分配文件偏移和虚拟地址区间;对
ET_EXEC类型的可执行文件:一般以某个固定基址为起点(例如 0x400000 + offset)PIE 与否是由 ELF 类型(
ET_EXECvsET_DYN)和代码生成方式决定的,理论上和“静态/动态链接”是正交的概念;但在目前主流 Linux 工具链中,**静态链接的可执行文件通常仍然生成为非 PIE 的
ET_EXEC**,即使指定了-fPIE -pie,实际也未必会得到真正的静态 PIE。因此,在分析实际二进制时,应以
readelf -h/checksec检查 ELF 类型和装载基址为准,而不是只看编译命令行参数。对
ET_DYN(包括共享库和 PIE):通常以 0 作为逻辑基址,真实装载时由内核 / 动态链接器整体平移,利于地址无关代码。
静态重定位(消耗
.rel.*/.rela.*) :在ET_REL的目标文件 中,每个要被重定位的节(比如.text/.data)通常有对应的重定位节:.rel.text/.rela.text:代码重定位;.rel.data/.rela.data:数据重定位。
其元素是
Elf*_Rel或Elf*_Rela,每一项包含:r_offset:当前目标文件中需要修正的位置;r_info:打包的“符号索引 + 重定位类型”;(RELA 情况下)
r_addend:显式 addend。
链接器做的事:
根据重定位节头的
sh_info找到“要被修正的是哪个节”(比如.text);通过
r_offset+ 该节在最终 ELF 中的起始地址,算出真正要 patch 的位置;用
r_info取出:- 需要引用的符号(从
.symtab找到对应Elf*_Sym); - 重定位类型(如
R_386_32/R_386_PC32等);
- 需要引用的符号(从
从符号表条目的
st_value(结合最终地址分配)得到符号在最终 ELF 中的地址或偏移;按照重定位类型的规则计算最终写回值,patch 到对应位置。
示例(32 位 x86 常见类型):
R_386_32:绝对地址形式,一般是S + A;R_386_PC32:PC 相对,一般是S + A - P;- 其中
S是符号地址,A是 addend,P是重定位入口地址。
- 其中
完成这一轮后:
- 目标文件里
.rel.text/.rel.data这类“静态重定位节”对最终可执行文件来说已经没用了, - 链接器一般会直接把它们丢掉,因此在
ET_EXEC/ET_DYN里通常看不到这些节(除非用特殊选项要求保留)。
对于静态链接程序(
-static):
绝大部分符号引用(包括 libc 等静态库里的函数)在这一步就被“彻底解决”,最终可执行文件里不再依赖外部符号。
对于动态链接程序(默认模式):
链接器只解决“自己能定死的”部分;
对需要在运行时由共享库提供的符号,会保留一部分“动态重定位任务”给动态链接器去做,相关信息会写入.dynsym/.dynstr/.rela.dyn/.rela.plt等节中。
生成运行时元数据
为了让内核 / 动态链接器 / 调试器能够正确装载、运行和分析这个 ELF,链接器还需要生成一堆“辅助结构”:
程序头表(Program Header Table)
- 若干
Elf*_Phdr条目,如PT_LOAD、PT_DYNAMIC、PT_INTERP等; - 告诉内核:文件中哪些区间要映射到内存哪里、权限是什么(R/W/X)。
- 若干
.interp/PT_INTERP(仅动态链接程序)- 里面是动态链接器路径,例如
/lib64/ld-linux-x86-64.so.2; - 让内核知道“启动这个程序前要先加载哪个解释器(动态链接器)”。
- 里面是动态链接器路径,例如
动态节
.dynamic/PT_DYNAMIC(动态链接相关)以
Elf*_Dyn数组的形式记录:- 依赖的共享库(
DT_NEEDED); - 动态符号表、字符串表的位置(
DT_SYMTAB/DT_STRTAB); - 动态重定位表的位置和大小(
DT_RELA*/DT_REL*); - 初始化 / 终止函数(
DT_INIT/DT_FINI/DT_INIT_ARRAY*/DT_FINI_ARRAY*)等;
- 依赖的共享库(
这些信息是动态链接器在运行时的“导航图”。
PLT / GOT(对动态链接程序)
为外部函数调用合成 PLT 代码段
.plt/.plt.sec和对应的 GOT 槽位.got.plt;在
.rela.plt/.rel.plt中为每个跳转槽位生成一个重定位条目,告诉动态链接器:- 第一次调用某个函数时应该如何解析符号、写入 GOT、并跳转过去;
- 或在 FULL RELRO +
-z now时一上来就把这些槽位填满。
程序执行过程
装载
在 Linux 中,装载(load/load in memory)指的是操作系统内核将一个 ELF 可执行文件从磁盘读取出来,并将其内容映射到进程的虚拟地址空间中,准备好让 CPU 可以从它的入口点开始执行的整个过程。
装载的本质是:内核清空当前进程的用户空间 → 加载新程序 → 设置入口 → 开始执行。
1 | 用户命令 → shell 调用 fork → 子进程调用 execve |
从 shell 到 execve
当我们在 shell 中执行一条命令时,实际上发生了以下流程:
bash进程调用fork()创建一个子进程;- 子进程调用
execve()执行新的 ELF 可执行程序; - 父进程继续执行,等待子进程结束。
其中 execve() 是 Linux 中非常核心的一个系统调用,简单来说,**execve() 就是“让当前进程去运行另一个程序”。**该函数原型如下:
1 | int execve(const char *pathname, char *const argv[], char *const envp[]); |
pathname:要执行的程序路径(可以是 ELF 文件、脚本等)argv[]:参数列表(传给main(int argc, char *argv[]))envp[]:环境变量列表
另外 glibc 提供了多个 exec 族 API(如 execl, execvp, execvpe 等)对其封装,最终都调用 execve()。
| 函数名 | 参数形式 | 是否查 PATH | 是否自带 envp | 调用示例 |
|---|---|---|---|---|
execl |
列表 | ❌ 否 | ❌ 否 | execl("/bin/ls", "ls", NULL); |
execlp |
列表 | ✅ 是 | ❌ 否 | execlp("ls", "ls", NULL); |
execle |
列表 + envp | ❌ 否 | ✅ 是 | execle("/bin/ls", "ls", NULL, envp); |
execv |
数组 argv[] |
❌ 否 | ❌ 否 | execv("/bin/ls", argv); |
execvp |
数组 argv[] |
✅ 是 | ❌ 否 | execvp("ls", argv); |
execvpe |
数组 + envp | ✅ 是 | ✅ 是 | execvpe("ls", argv, envp); |
提示
参数形式指的是怎么把参数(
argv)传给要执行的程序。列表形式指的是一个一个地写参数(就是函数的变长参数)。例如
execl:1
execl("/bin/ls", "ls", "-l", "/tmp", NULL);
这种形式里,函数的参数是分开的,最终内部会构造出一个
argv[]数组:1
char *argv[] = {"ls", "-l", "/tmp", NULL};
数组形式指的是需要自己先准备好一个
argv[]数组,把它直接传进去:1
2char *argv[] = {"ls", "-l", "/tmp", NULL};
execv("/bin/ls", argv);
是否查
PATH指的是系统要不要自动去$PATH环境变量指定的目录中查找可执行文件的位置。1
2
3execlp("ls", "ls", NULL); // ✅ 查 PATH,会找到 /bin/ls 或 /usr/bin/ls
execl("/bin/ls", "ls", NULL); // ❌ 不查 PATH,需要你手动给出完整路径在 Linux 中,环境变量
PATH是一串目录组成的列表,比如:1
2echo $PATH
# /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin当你调用
execvp("ls", argv)时,它会依次在这些目录中查找有没有可执行文件叫"ls",直到找到为止。- 如果找到了,比如
/bin/ls,就用它去执行; - 如果没找到,就报错
ENOENT。
- 如果找到了,比如
是否自带
envp这个函数是否支持你传入自定义envp(不然只能用默认的)。envp是环境变量数组,是一个char *envp[]类型,例如:1
char *envp[] = {"PATH=/bin:/usr/bin", "USER=sky123", NULL};
- 如果函数 没有
envp参数,那就只能自动使用当前进程的环境变量(通过全局变量environ获取); - 如果函数 有
envp参数(比如execle,execvpe),你可以自己传一组新的环境变量数组,用于改变目标程序执行时的环境。
- 如果函数 没有
下面是一个简易的 bash 程序实现:
1 |
|
execve 的内核的实现
execve() 是 Linux 中最核心的“程序执行”系统调用。它会将当前进程的用户态空间完全清空,然后加载新的 ELF 程序及其依赖库,并最终跳转到新程序入口点执行。
execve 整体的系统调用流程如下:
1 | glibc // 用户态 C 库;调用 exec 系列 API |
简单来说 execve 的执行逻辑就是就是判断可执行文件的魔数然后调用对应的回调函数加载执行可执行文件。
魔数(Magic Number) 指文件头部的一段固定字节序列,用来快速标识文件类型或版本。它是“文件格式的身份证”,让操作系统或应用程序无需解析整个文件即可知道该用哪种解析/加载器处理。
例如在类 UNIX 操作系统中,文件头以
#!(称为 Shebang)开头,是专门用于标识“这是一个脚本文件”及其对应解释器路径的魔数格式。而对于 ELF 格式的可执行文件,其魔数是:
\x7FELF。
对于可执行文件,在 fs/binfmt_elf.c 中定义了加载执行该类型文件的回调函数 load_elf_binary。
1 | static struct linux_binfmt elf_format = { |
load_elf_binary() 是 Linux 内核真正把 ELF 映像搬进新进程地址空间并把 CPU 跳到入口地址的函数,该函数的主要逻辑为:
验证 ELF 头
- 检查魔数
\x7FELF、位宽、字节序、e_type(ET_EXEC/ET_DYN)。 - 读取并验证 Program‑Header Table 数量与大小。
- 检查魔数
查找
.interp段(如有)- 若存在
PT_INTERP,读出动态链接器路径/lib*/ld-linux*.so.*。 - 打开链接器文件,为后续映射做准备。
有
PT_INTERP的 ELF,其真正的“解释器”就是这个ld-linux*.so.*;跟#!/usr/bin/python3的脚本会交给 python 解释器,有点类似。1
./a.out arg1 arg2
内核等价于偷偷做了:
1
/lib64/ld-linux-x86-64.so.2 ./a.out arg1 arg2
你也可以自己手动这么干,比如:
1
2
3
4
5# 看看当前程序的解释器是谁
readelf -l ./a.out | grep 'interpreter'
# 手动调用动态链接器来跑它
/lib64/ld-linux-x86-64.so.2 ./a.out arg1 arg2前提是:
- 这个 ELF 是动态链接的(有
PT_INTERP); - 你用的路径要跟
.interp里的一致或兼容。
对于静态链接程序(没
PT_INTERP),就不会走动态链接器了,内核直接把它当普通ET_EXEC装载执行,用ld-linux.so去跑就没意义。- 若存在
加载 Program‑Header
PT_LOAD段- 逐段
mmap.text/.rodata/.data/.bss等到进程地址空间; - 计算
load_bias(PIE 随机基址)并更新start_code/end_code等 mm 统计字段; - 为
.bss/heap 调用set_brk()分配零页。
- 逐段
设置栈与辅助向量 (
setup_arg_pages()→create_elf_tables())- 把
argv[]、envp[]、auxv[]拷到新栈; - 在 auxv 填入
AT_PHDR,AT_ENTRY,AT_BASE,AT_RANDOM等,供链接器/程序读取。
- 把
加载并映射动态链接器(若存在)
load_elf_interp()把ld.so自身映射进地址空间;- 记录其加载基址,用作
AT_BASE及后续重定位。
切换到新进程映像
flush_old_exec()→ 清掉旧 mm;install_exec_creds()→ 安装新 UID/GID/LSM 凭据;- 随机化栈 / brk(若启用 ASLR)。
确定入口地址并启动线程
- 静态 ELF:入口 =
e_entry + load_bias; - **动态 ELF (PIE)**:入口 = 链接器入口;链接器完成重定位后再跳到主程序
_start; start_thread(regs, elf_entry, stack_top)把rip/eip指向入口并返回用户态。
- 静态 ELF:入口 =
一旦 start_thread() 返回到用户空间,CPU 已在 新程序入口 指令处运行;自此,旧进程代码与所有旧 .so 全部被替换。
进程虚拟地址空间
在现代操作系统中,每个进程都运行在自己的虚拟地址空间(Virtual Address Space)中。所谓虚拟地址空间,是操作系统提供给进程的一种抽象地址空间:
- 每个进程拥有独立的地址空间,互相隔离。
- 虚拟地址空间由连续的虚拟地址构成,而不是物理地址。
- 操作系统通过内存管理单元(MMU)将虚拟地址翻译为实际的物理地址。
虚拟地址空间让进程以为自己独占内存空间,简化了程序设计,并提高了系统的安全性和稳定性。
通常来说,一个进程(关闭 PIE 且动态链接)的进程空间布局如下:
1 | 0x0000_0000_0000 ── NULL page (不可访问,解引用触发 SIGSEGV) |
其中常见的段含义如下:
| 区域 / 段 | 典型权限 | 详细说明 |
|---|---|---|
.text |
R‑X |
- 代码段(text segment),包含可执行的 机器指令。- 在可执行文件中,此段往往是只读 + 可执行,避免被恶意篡改。- 如果启用了 NX(No-eXecute)保护,除了此段外,其他内存区域将被禁止执行(W^X 策略)。 |
.rodata |
R-- |
- Read-Only Data 段。- 存放 字符串常量、const 修饰的全局变量、C++ 的 虚表(vtable) 等。- 映射为只读,防止运行期间被意外或恶意修改。 |
.data |
RW- |
- 已初始化的全局变量、静态变量(.data段)。- 例如:int x = 42; 会被存入此区域。 |
.bss |
RW- |
- Block Started by Symbol(BSS 段),用于未初始化的全局 / 静态变量。- 比如:int y; 会占据此段空间。- 在加载时由内核自动用 0 填充,不会占用磁盘文件空间(仅占内存页)。 |
.got / .plt |
.got: RW-``.plt: R‑X |
- GOT(Global Offset Table) 保存运行时解析出的函数 / 全局变量地址。- PLT(Procedure Linkage Table) 是延迟绑定跳板,调用函数时会跳到 .plt 中间接跳转到实际地址。- 两者配合实现 dlopen() 和延迟绑定机制。 |
.dynamic |
R-- |
- 存放动态链接信息,如:符号表、重定位表偏移、需要的共享库名等。- 程序启动时由动态链接器(如 ld-linux.so)读取并处理。 |
.init_array / .fini_array |
RW- |
- 分别用于 C/C++ 程序的构造函数(初始化)和析构函数(结束)列表。- 编译器将 __attribute__((constructor)) 或全局对象构造函数地址放入 .init_array,在启动时自动调用。 |
| Heap(堆) | RW- |
- 程序通过 malloc() / new 等动态分配的内存区域。- 初始堆由 brk() 创建,超出部分通过 mmap() 生成匿名页。- 向高地址扩展。 |
| Stack(栈) | RW- |
- 包含函数调用栈帧、局部变量、返回地址等信息。- 默认 8MB 左右空间,可通过 ulimit -s 设置。- argv[], envp[], auxv[] 也在进程启动时由内核构造在此处。- 向低地址扩展;底部设置 guard page(不可访问)防溢出。 |
| vDSO / vvar | R-- |
- vDSO(Virtual Dynamic Shared Object)是内核映射到用户空间的共享库,提供 gettimeofday() 等系统调用的用户态实现,加快访问速度(免陷入内核)。- vvar 是 vDSO 访问的变量页,如时钟源信息。- cat /proc/self/maps 可见它们在栈附近。 |
| mmap() 区域 | R--/RW-/RWX 等 |
- 使用 mmap() 映射的所有区域:包括动态链接库(.so 文件)、匿名页、文件映射、JIT 编译代码区等。- 运行时由内核动态分配,段数量不定;常见于 JavaScript 引擎、Python、动态模块等。 |
进程栈的初始化
当我们执行:
1 | ls /home |
bash 最终会调用:
1 | execve("ls", argv, envp); |
从这一刻开始,内核接管控制权,大致流程(对 ELF 程序)是:
do_execveat_common()解析参数,识别这是 ELF。调用
load_elf_binary()(fs/binfmt_elf.c):- 释放旧地址空间,创建新的
mm_struct; - 映射 ELF 的
PT_LOAD段(代码段、数据段等); - 调用
setup_arg_pages()创建用户栈 VMA(这里会处理 ASLR + 栈/映射区间隔); - 调用
create_elf_tables()把argc/argv/envp/auxv布置到栈上; - 设置寄存器:指令指针(IP)= 入口地址、栈指针(SP)= 刚搭好的栈顶。
- 释放旧地址空间,创建新的
从内核返回用户态,从入口地址开始执行(静态程序直接是你的
_start,动态程序是ld-linux.so的_start)。
在 load_elf_binary() 中,内核先选一个靠近 STACK_TOP 的位置作栈顶:
1 | unsigned long stack_top = STACK_TOP; |
randomize_stack_top() 会在 STACK_TOP 附近向下随机偏移一段(典型范围是 ~8MB):
1 |
|
生成一个随机数
random_variable = get_random_int() & STACK_RND_MASK;random_variable <<= PAGE_SHIFT(按页对齐);对向下生长的栈,返回:
1
stack_top = PAGE_ALIGN(STACK_TOP) - random_variable;
这一步在 8MB 左右的范围内随机(
STACK_RND_MASK决定上限)。
接着,在 create_elf_tables() 里还会调用 arch_align_stack() 做一次细粒度随机 + 16 字节对齐:
1 | unsigned long arch_align_stack(unsigned long sp) |
这两步叠加效果:
- 每次
execve(),初始栈地址都不一样(ASLR); - 最终
%rsp会被对齐到 16 字节,满足 System V ABI 要求,所以你总能看到栈地址低 4 bit 为 0,但高几位总在变。
只做 ASLR 还不够。历史上 Linux 只有“一页 guard page”,结果出现了著名的 Stack Clash:用户栈可以一次性递归/alloc 大量空间,一口气“跳过”那一页,直接撞上 mmap 区,引起堆栈重叠,从而打穿沙箱。
为此,内核引入了一个全局参数 **stack_guard_gap**,表示栈和其它映射之间要预留多少页不映射(guard 区):
官方文档(Documentation/admin-guide/kernel-parameters.txt)说明:
stack_guard_gap=:距离主栈前(栈向下增长时)或后(栈向上增长时)预留多少页不用于映射,默认是 256 页。
在通用 mm 代码里,有两个辅助函数专门考虑这个 gap:
1 | static inline unsigned long vm_start_gap(struct vm_area_struct *vma) |
这些函数被 mmap 布局代码用来保证:在栈 VMA 周围预留一段 stack_guard_gap 大小的空洞,别的 VMA 不会贴得太近。
再看 top‑down mmap 布局(很多 64 位平台使用),mmap_base() 里会参考当前 RLIMIT_STACK 和 stack_guard_gap 计算 stack 与 mmap 之间的“安全间隔 gap”:
1 | static unsigned long mmap_base(unsigned long rnd, struct rlimit *rlim_stack) |
关键点:
gap 至少包含:
- 栈允许的最大大小(
RLIMIT_STACK); stack_guard_gap(例如缺省 256 页 ≈ 1MB 左右);- 外加考虑栈随机化的那一段。
- 栈允许的最大大小(
gap 被夹在
[MIN_GAP, MAX_GAP]之间,防止搞得太大或太小。mmap 顶端(
mmap_base)会在TASK_SIZE - gap之下,留出这个 gap 给栈增长和 guard 使用。
直观理解:
内核在用户栈和 mmap 区之间留出了一块至少
stack_guard_gap+ 随机偏移 + RLIMIT_STACK 的 “空洞”,栈要想撞上 mmap,必须先填满自己允许的栈大小,还得跨过 guard 空洞,Stack Clash 难度就被拉高很多。
栈空间搞定之后,create_elf_tables() 会在栈顶附近按 ELF 规范布置进程参数和“辅助信息”。
在程序初始状态的栈如下图所示:
pwndbg> stack 40
00:0000│ rsp 0x7fffffffdf28 —▸ 0x7ffff7c29d90 (__libc_start_call_main+128) ◂— mov edi, eax
01:0008│ 0x7fffffffdf30 —▸ 0x7fffffffe038 —▸ 0x7fffffffe3ba ◂— '/usr/bin/ls'
02:0010│ 0x7fffffffdf38 —▸ 0x555555558d10 ◂— endbr64
03:0018│ 0x7fffffffdf40 ◂— 0x2f7fa5910
04:0020│ 0x7fffffffdf48 —▸ 0x7fffffffe038 —▸ 0x7fffffffe3ba ◂— '/usr/bin/ls'
05:0028│ 0x7fffffffdf50 ◂— 0
06:0030│ 0x7fffffffdf58 ◂— 0xea1debf161b77c7f
07:0038│ 0x7fffffffdf60 —▸ 0x7fffffffe038 —▸ 0x7fffffffe3ba ◂— '/usr/bin/ls'
08:0040│ 0x7fffffffdf68 —▸ 0x555555558d10 ◂— endbr64
09:0048│ 0x7fffffffdf70 —▸ 0x555555574fd8 —▸ 0x55555555ab40 ◂— endbr64
0a:0050│ 0x7fffffffdf78 —▸ 0x7ffff7ffd040 (_rtld_global) —▸ 0x7ffff7ffe2e0 —▸ 0x555555554000 ◂— 0x10102464c457f
0b:0058│ 0x7fffffffdf80 ◂— 0x15e2140edfd37c7f
0c:0060│ 0x7fffffffdf88 ◂— 0x15e204745b3b7c7f
0d:0068│ 0x7fffffffdf90 ◂— 0x7fff00000000
0e:0070│ 0x7fffffffdf98 ◂— 0
... ↓ 3 skipped
12:0090│ 0x7fffffffdfb8 ◂— 0xea3da6237c5e9c00
13:0098│ 0x7fffffffdfc0 ◂— 0
14:00a0│ 0x7fffffffdfc8 —▸ 0x7ffff7c29e40 (__libc_start_main+128) ◂— mov r15, qword ptr [rip + 0x1f0159]
15:00a8│ 0x7fffffffdfd0 —▸ 0x7fffffffe050 —▸ 0x7fffffffe3cc ◂— 'SYSTEMD_EXEC_PID=1484'
16:00b0│ 0x7fffffffdfd8 —▸ 0x555555574fd8 —▸ 0x55555555ab40 ◂— endbr64
17:00b8│ 0x7fffffffdfe0 —▸ 0x7ffff7ffe2e0 —▸ 0x555555554000 ◂— 0x10102464c457f
18:00c0│ 0x7fffffffdfe8 ◂— 0
19:00c8│ 0x7fffffffdff0 ◂— 0
1a:00d0│ 0x7fffffffdff8 —▸ 0x55555555aaa0 ◂— endbr64
1b:00d8│ 0x7fffffffe000 —▸ 0x7fffffffe030 ◂— 2
1c:00e0│ 0x7fffffffe008 ◂— 0
1d:00e8│ 0x7fffffffe010 ◂— 0
1e:00f0│ 0x7fffffffe018 —▸ 0x55555555aac5 ◂— hlt
1f:00f8│ 0x7fffffffe020 —▸ 0x7fffffffe028 ◂— 0x1c
20:0100│ 0x7fffffffe028 ◂— 0x1c
21:0108│ 0x7fffffffe030 ◂— 2
22:0110│ rsi r12 0x7fffffffe038 —▸ 0x7fffffffe3ba ◂— '/usr/bin/ls'
23:0118│ 0x7fffffffe040 —▸ 0x7fffffffe3c6 ◂— 0x595300656d6f682f /* '/home' */
24:0120│ 0x7fffffffe048 ◂— 0
25:0128│ rdx 0x7fffffffe050 —▸ 0x7fffffffe3cc ◂— 'SYSTEMD_EXEC_PID=1484'
26:0130│ 0x7fffffffe058 —▸ 0x7fffffffe3e2 ◂— 'SSH_AUTH_SOCK=/run/user/1000/keyring/ssh'
27:0138│ 0x7fffffffe060 —▸ 0x7fffffffe40b ◂— 'SESSION_MANAGER=local/ubuntu:@/tmp/.ICE-unix/1452,unix/ubuntu:/tmp/.ICE-unix/1452'
pwndbg> telescope &environ 1
00:0000│ 0x7ffff7ffe2d0 (environ) —▸ 0x7fffffffe050 —▸ 0x7fffffffe3cc ◂— 'SYSTEMD_EXEC_PID=1484'
pwndbg> vmmap 0x7fffffffe050
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
Start End Perm Size Offset File (set vmmap-prefer-relpaths on)
0x7ffff7ffd000 0x7ffff7fff000 rw-p 2000 39000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
► 0x7ffffffde000 0x7ffffffff000 rw-p 21000 0 [stack] +0x20050
从低地址到高地址的大致布局(低地址 = 初始 %rsp 指向的位置):

以 ls /home 为例:
argc = 2(一般为argv[0] = "/usr/bin/ls",argv[1] = "/home");argv是一个以 NULL 结尾的指针数组,数组元素指向后面“字符串区”的具体 C 字符串;envp同理,是以 NULL 结尾的char *数组,例如:1
2
3envp[0] -> "SYSTEMD_EXEC_PID=1484"
envp[1] -> "SSH_AUTH_SOCK=/run/user/1000/..."
...
C 运行时里全局变量 char **environ 一般就直接指向 envp[0]。
辅助信息数组(Auxiliary Vector)是内核给用户态“塞的一小包元数据”。内核在进程启动时,会在用户栈上布置一段
(a_type, a_val)形式的辅助向量 auxv,用来向用户态传递 ELF 布局、硬件特性、随机种子、UID/GID 等信息。
- 对 动态链接程序,动态链接器(
ld-linux.so)会优先读取其中的AT_PHDR、AT_PHNUM、AT_BASE、AT_ENTRY等条目,用来完成重定位和把控制权交给真正的程序入口。- 对 静态链接程序,没有动态链接器参与,但 libc 和应用本身仍然可以通过
getauxval()或/proc/self/auxv读取 auxv(如页大小、硬件能力、随机种子等)。以 32 位为例(64 位只是字段宽度不同),
Elf32_auxv_t的定义如下(节选自elf.h):
2
3
4
5
6
7
8
9
10
11
{
uint32_t a_type; /* Entry type */
union
{
uint32_t a_val; /* Integer value */
/* We use to have pointer elements added here. We cannot do that,
though, since it does not work when using 32-bit definitions
on 64-bit platforms and vice versa. */
} a_un;
} Elf32_auxv_t;其中
a_un是一个联合体,目前实际上只用到其中的a_val成员:
在 32 位结构体里是
uint32_t,在 64 位结构体里是 64 位无符号整型;从“语义”上看,它可能代表两类东西:
- 普通整数:比如
AT_PAGESZ、AT_FLAGS等;- 地址值:比如
AT_PHDR、AT_BASE、AT_ENTRY、AT_RANDOM、AT_EXECFN等,本质是一个指针,被强行塞进整型里。
a_type指示这一条 auxv 的类型,决定了a_val的含义。常见类型包括:
AT_NULL (0)
辅助向量列表结束标志。最后一条一定是(AT_NULL, 0)。
AT_IGNORE (1)
忽略此条目,历史兼容保留,一般不用。
AT_EXECFD (2)
可执行文件的文件描述符(配合fexecve()等使用)。多数普通execve(path, ...)的程序不会设置。
AT_PHDR (3)
程序头表(Program Header Table)在内存中的地址。动态链接器用它来遍历Elf*_Phdr,找到PT_PHDR、PT_DYNAMIC等段。
AT_PHENT (4)
程序头表中每个条目的大小(字节数),通常是sizeof(Elf*_Phdr)。
AT_PHNUM (5)
程序头表中条目的数量,对应 ELF 头里的e_phnum。
AT_PAGESZ (6)
系统页大小(如 4096)。libc/malloc/动态链接器会用它做页对齐和内存映射。
AT_BASE (7)
动态链接器自身的装载基址(比如/lib64/ld-linux-x86-64.so.2在进程地址空间中的基地址)。
对纯静态程序通常为 0。
AT_FLAGS (8)
各种标志位,含义依具体实现和 ABI,一般调试器/动态链接器内部使用。
AT_ENTRY (9)
程序入口点虚拟地址(最终要跳到的地址),和 ELF 头的e_entry一致(考虑装载基址后)。
AT_NOTELF (10)
标记“原始执行文件不是标准 ELF”,某些兼容场景用,一般 ELF 程序不会碰到。
AT_UID/AT_EUID/AT_GID/AT_EGID
程序的真实/有效 UID、GID,libc、PAM、沙箱等可能会用。
AT_SECURE
非 0 表示当前进程处于“安全执行模式”,例如 setuid 程序。libc 会据此忽略部分不安全的环境变量。
AT_RANDOM
指向栈上一块 16 字节的随机数据。glibc 用它初始化栈 canary、rand()种子等安全相关内容。
AT_EXECFN
指向启动该程序时使用的路径字符串(通常是argv[0]对应的那一块)。注意:并不是每个进程都会拥有所有这些条目,内核会根据实际情况填充一部分,剩下的根本不会出现。
这些值的“解释”由 libc / 动态链接器负责,你在 glibc 里可以通过
getauxval(AT_XXX)读到。
内核把 IP/SP 设好后,开始执行用户态入口:
- 静态链接程序:IP 直接指向你的
_start; - 动态链接程序:IP 指向
ld-linux.so的_start,它先处理自己的重定位、扫描 auxv、构建链表link_map等,然后再跳到目标 ELF 的_start。
以 glibc + x86‑64 为例,你的程序里的 _start(crt1.S)做的事情大致是:
1 | ENTRY (_start) |
_start先从栈里弹出argc,算出argv指针:popq %rsi→rsi = argcmov %rsp, %rdx→rdx = argv
and $~15, %rsp,直接把%rsp底 4 bit 清零,强制对齐到 16 字节边界。内核把
argc/argv/envp/auxv布好栈,把控制权交给_start,此时栈不一定是满足 SysV ABI 要求的 16 字节对齐(内核只保证基本合理性和自己的对齐策略)。这一步保证
__libc_start_main这类 C 函数被调用时,栈已经按 x86‑64 SysV ABI 要求对齐好了。紧接着
pushq %rax、pushq %rsp等,最后再call __libc_start_main。1
__libc_start_main(main, argc, argv, init, fini, ..., stack_end);
__libc_start_main() 里会
设置全局变量
environ = envp;从 auxv 提取
AT_*信息,完成 TLS / canary / locale 等初始化;调用构造函数(
.init_array);最后才调用用户的:
1
return main(argc, argv, envp);
动态链接
动态链接(Dynamic Linking)是指把“某些符号的解析和重定位工作”推迟到程序装载时甚至运行时再做:
可执行文件里只记录“我需要哪些共享库、哪些导入符号”;
程序启动时由 动态链接器(
ld-linux.so) 根据.dynamic/.dynsym/.rela.*等信息:- 把各个共享对象(
.so)映射进内存; - 解析导入符号;
- 对 GOT/数据等做动态重定位;
- 然后把控制权交给程序入口。
- 把各个共享对象(
在 ELF 的动态链接里,有两个核心限制:
- 代码要支持 位置无关(共享库、PIE),指令里不能写死绝对地址;
- 可执行文件在链接阶段还不知道外部函数/变量最终会来自哪个
.so,地址要到运行时由动态链接器决定。
于是就出现了两张表:
- GOT(Global Offset Table):纯数据表,存“将来要用到的各种地址”(变量地址、函数地址等);
- PLT(Procedure Linkage Table):纯代码表,存“调用外部函数用的跳板 stub”。
基本模式:
代码 → 跳到 某个 PLT 入口 → 通过 GOT 槽位 找到目标地址 → 真正的函数 / 变量。
这样:
编译/链接时,代码里只需要写相对地址(PC-relative)到 PLT/GOT;
运行时动态链接器填补 GOT,PLT 就能通过 GOT 间接跳转到真正的实现;
可以支持:
- 共享库复用;
- PIE;
- lazy binding 等。
ELF 相关结构
.interp 段
在需要“程序解释器”的 ELF 可执行文件中(典型就是动态链接的可执行文件,包括 PIE),通常会有一个名为 .interp 的 节(section)。
- 节名:
.interp - 一般类型:
SHT_PROGBITS,带SHF_ALLOC标志 - 通常会被映射到一个 程序头(Program Header),类型为
PT_INTERP的段(segment)
注意:ELF 规范里 关键的是
PT_INTERP这个 Program Header,.interp只是实现上常见的节名而已。
.interp 的内容非常简单:
- 内容是一段 以
\0结尾的 ASCII 字符串 - 这段字符串给出的是 “程序解释器(Program Interpreter)”的路径
- 在 Linux 上,绝大多数情况下,这个解释器就是 动态链接器(dynamic linker / loader)
常见(但不是唯一正确)的例子:
- x86_64 + glibc:
/lib64/ld-linux-x86-64.so.2 - i386 + glibc:
/lib/ld-linux.so.2 - musl libc:如
/lib/ld-musl-x86_64.so.1等
所以,**不能说 .interp 里“就是” /lib64/ld-linux-x86-64.so.2**,
应该说:
.interp中保存着一个以\0结尾的路径字符串,指定该 ELF 需要的“程序解释器”(在 Linux 上通常是动态链接器),路径具体取决于架构和发行版。
从内核视角看,关键是 程序头表中的 PT_INTERP 条目:
当你
execve()一个 ELF 文件时,内核解析其 Program Header Table:如果发现有一个
PT_INTERP条目:- 读取其中的路径字符串(文件偏移一般指向
.interp的内容) - 把该路径对应的 ELF 文件(通常是动态链接器,如
ld-linux-*.so.*)加载到内存 - 让这个“解释器”接管原始可执行文件的装载和运行
- 读取其中的路径字符串(文件偏移一般指向
如果 **没有
PT_INTERP**:- 内核直接把当前 ELF 当作不需要外部解释器的程序加载执行(在常见场景下就是“静态链接程序”)
从工具和实践角度看:
- 带
PT_INTERP的 ELF 一般就是“动态链接的可执行文件(包括 PIE)” - 没有
PT_INTERP的,则一般是静态链接的可执行文件
- 带
更严谨地说:
- “是不是动态链接程序”的判断,核心依据是 是否存在
PT_INTERP(以及通常也有PT_DYNAMIC);.interp只是保存路径字符串的那块数据区域,内核真正关心的是指向它的PT_INTERPprogram header,而不是“有没有一个名叫.interp的节”。
.dynamic 段
在使用动态链接的 ELF 可执行文件或共享对象(共享库)中,有一个非常关键的结构:
**Dynamic Section(动态节) .dynamic**。
- 从 节(Section) 的角度看:名字就叫
.dynamic。 - 从 段(Segment) 的角度看:程序头表中有一个类型为
PT_DYNAMIC的段,它指向这块区域。
动态链接器(ld.so)真正依赖的是这个PT_DYNAMIC段 来找到.dynamic中的内容。
.dynamic 里存放的是一系列“键值对式”的条目,告诉动态链接器:
- 依赖了哪些共享库;
- 动态符号表和字符串表在哪里;
- 重定位表在哪里、多大;
- 初始化 / 终止函数在哪里;
- 以及其他动态链接需要的各种参数。
.dynamic 区域是一个以 Elf*_Dyn 为元素的数组,以 DT_NULL 结尾。
以 32 位为例(你原来的结构体是对的,只是 64 位略有不同):
1 | /* Dynamic section entry. */ |
64 位版本(简化)大致是:
1 | typedef struct { |
含义:
d_tag:表明这一项是什么类型(DT_XXX)。d_un.d_val/d_un.d_ptr:对于“一般整数值”的条目,用
d_val;对于“地址(虚拟地址)”类型的条目,用
d_ptr。d_ptr一般是虚拟地址,不是文件偏移;
最后一项是
d_tag == DT_NULL,表示.dynamic结束。
d_tag 常见的有下面几种类型:
符号表和字符串表相关
DT_SYMTAB
- 含义:动态符号表的虚拟地址。
- 使用字段:
d_un.d_ptr。- 通常指向
.dynsym节的起始地址。- 动态链接器通过这里找到所有“参与动态链接”的符号(函数 / 变量名等)。
DT_STRTAB
- 含义:动态字符串表的虚拟地址。
- 使用字段:
d_un.d_ptr。- 通常指向
.dynstr(不是.synstr,你原文这里写错了)。- 符号名字、
DT_NEEDED/DT_SONAME等引用的字符串,都存放在这个表中。
DT_STRSZ
- 含义:动态字符串表的大小(字节数)。
- 使用字段:
d_un.d_val。符号查找加速相关
DT_HASH
- 含义:传统 SysV 风格符号哈希表的虚拟地址。
- 使用字段:
d_un.d_ptr。- 通常对应
.hash节,用于加速符号查找。- 现代系统上常见 **
DT_GNU_HASH**,对应.gnu.hash,是另一套更高效的哈希机制。名字 / 路径相关
这些条目通常不直接存放指针,而是:
d_un.d_val= 在 动态字符串表(DT_STRTAB指向的表) 中的偏移。
DT_SONAME
- 共享对象自己的“逻辑名称”(如
libc.so.6),- 动态链接器和
ldd等工具会使用它显示库名。- 常存在于共享库(ET_DYN),在可执行文件中一般不用。
DT_NEEDED
- 表示“本对象依赖的一个共享库名字”。
- 一个库 / 可执行文件可以有多个
DT_NEEDED,每个条目代表一个依赖库。- 动态链接器通过这些名字去搜索并加载对应的
.so文件。**
DT_RPATH**(已废弃)
- 指向一个以
:分隔的库搜索路径字符串(字符串表偏移)。- 旧机制,已被
DT_RUNPATH替代,一般不推荐继续使用。- 同样使用
d_un.d_val作为字符串表偏移。初始化 / 终止相关
DT_INIT
- 含义:单个初始化函数的虚拟地址。
- 使用字段:
d_un.d_ptr。- 动态链接器在装载该对象、在
main之前会调用这个函数一次。- 现代编译器更多使用
DT_INIT_ARRAY/DT_INIT_ARRAYSZ来支持一组构造函数。
DT_FINI
- 含义:单个终止函数的虚拟地址。
- 使用字段:
d_un.d_ptr。- 程序退出或卸载共享对象时由动态链接器调用。
- 对应的新形式是
DT_FINI_ARRAY/DT_FINI_ARRAYSZ。重定位相关
DT_REL/DT_RELA
含义:重定位表的起始虚拟地址。
DT_REL对应不带附加 addend 的重定位表(Elf*_Rel);
DT_RELA对应带 addend 的重定位表(Elf*_Rela)。使用字段:
d_un.d_ptr。实际上还会配合以下条目一起使用:
DT_RELSZ/DT_RELASZ:重定位表总大小;DT_RELENT/DT_RELAENT:每个重定位项的大小;- 还有专门给 PLT 的
DT_JMPREL/DT_PLTRELSZ/DT_PLTREL等。动态链接器根据这些信息,遍历重定位项,为 GOT/PLT、全局变量等打上正确的地址。
动态符号表(.dynsym)
动态链接时,动态链接器需要知道:
- 本模块导出给别人的符号(供别的
.so/ 主程序引用); - 本模块导入自别人的符号(需要从其它
.so里解析)。
这些信息就集中保存在 动态符号表 .dynsym 中:
.dynsym的元素类型仍然是Elf*_Sym数组。它只包含“和动态链接相关”的那部分符号:
- 参与导入 / 导出 / 重定位的全局符号、弱符号;
- 不包含纯本地、只在编译期用的内部符号(那种在
.symtab里才完整出现)。
一个 ELF 通常可能同时有:
- **
.symtab**:静态符号表,给链接器、调试器用,内容“尽量全”(编译期视图); - **
.dynsym**:动态符号表,给动态链接器用,只保留动态链接需要的那一部分符号(运行期视图)。
- **
和 .symtab 一样,.dynsym 也需要配套的辅助表:
**
.dynstr**:动态字符串表st_name字段的字符串偏移就是相对于.dynstr的;- 哪个节是
.dynstr,由.dynsym节头里的sh_link指明。
符号哈希表:
- 老式:
.hash - 新式:
.gnu.hash - 主要用于加速动态链接器查符号,不查整个
.dynsym线性表。
- 老式:
总结一句:
.symtab是“给链接器 / 调试器看的完整符号视图”,.dynsym是“给动态链接器看的精简符号视图”。
动态重定位表(.rel.dyn / .rela.dyn、.rel.plt / .rela.plt)
在 静态链接 中,未知地址在链接阶段就能确定;链接器用 .rel.text / .rel.data 等把地址 patch 好后,这些重定位信息就可以丢掉。
但在 动态链接 中,导入符号(来自其它 .so)的地址要到 运行时 才能确定:
- 比如程序哪个时刻才加载哪个
.so; - PIE / 共享库的装载基址每次运行都可能不同(ASLR)。
所以必须把一部分“待修正的引用”延后到动态链接器运行时再做,这就需要“动态重定位表”。
一般数据和非 PLT 的重定位需要 .rel.dyn 或 .rela.dyn(具体用 REL 还是 RELA 看 ABI),节类型为 SHT_REL / SHT_RELA,元素为 Elf*_Rel / Elf*_Rela。
这类节的主要作用是修正各种“非 PLT 的”地址引用,包括但不限于:
.got中存放的指针(例如全局变量、函数指针等);.data/.bss等数据段中保存的绝对地址;- 某些位置无关代码中需要运行时计算的地址等。
可以类比为“动态版本的 .rel.data / .rela.data”,只不过它修的是:
“装载后在内存中的位置”,由动态链接器来处理(通常在程序启动阶段或按需处理)。
PLT/GOT 上的函数调用重定位需要 .rel.plt 或 .rela.plt;这种重定位的目标位置主要在 .got.plt 里,即和 PLT 表关联的 GOT 槽位;
因此这类节的主要作用是修正外部函数调用的入口,典型流程:
对某个外部函数
foo:- 代码调用
foo@plt; foo@plt的 stub 会通过.got.plt中的槽位间接跳转;.rel.plt/.rela.plt中为这个槽位生成一个重定位条目。
- 代码调用
动态链接器根据这些条目:
- 首次调用时解析符号地址,写入对应 GOT 槽位;
- 之后直接从 GOT 跳到真正的
foo实现(延迟绑定),
或在 FULL RELRO +-z now场景下启动时就一次性填满。
可以粗略把 .rel.plt / .rela.plt 想象成:
“动态版本的 .rel.text 里那部分跟函数调用相关的重定位信息,但专门抽出来服务于 PLT”。
GOT 表(.got/.got.plt)
在常见的 System V 风格 ELF(比如 x86‑64 glibc)里,GOT 通常“逻辑上”分两块:
.got用来存放数据引用相关的地址(或偏移),比如:
- 全局变量;
- 常量表;
- 函数指针等。
.got.plt- 用来存放通过 PLT 调用的外部函数的地址槽位。
有些实现可能只生成一个 .got,把函数/数据混在一起,这是实现细节,不是 ELF 规范强制的。
在 glibc + i386 / x86‑64 下,.got.plt 前几项通常留给动态链接器自用(懒绑定相关),常见约定类似:
pwndbg> got Filtering out read-only entries (display them with -r or --show-readonly) State of the GOT of /home/ubuntu/Desktop/pwn: GOT protection: Partial RELRO | Found 1 GOT entries passing the filter [0x555555558018] system@GLIBC_2.2.5 -> 0x555555555030 ◂— endbr64 pwndbg> telescope 0x555555558018-8*3 00:0000│ 0x555555558000 (_GLOBAL_OFFSET_TABLE_) ◂— 0x3df8 01:0008│ 0x555555558008 (_GLOBAL_OFFSET_TABLE_+8) —▸ 0x7ffff7ffe2e0 —▸ 0x555555554000 ◂— 0x10102464c457f 02:0010│ 0x555555558010 (_GLOBAL_OFFSET_TABLE_+16) —▸ 0x7ffff7fd8d30 (_dl_runtime_resolve_xsavec) ◂— endbr64 03:0018│ 0x555555558018 (system@got[plt]) —▸ 0x555555555030 ◂— endbr64 04:0020│ 0x555555558020 (data_start) ◂— 0 05:0028│ 0x555555558028 (__dso_handle) ◂— 0x555555558028 (__dso_handle) 06:0030│ 0x555555558030 (tcp_port) ◂— 0x16 07:0038│ 0x555555558038 ◂— 0 pwndbg> telescope $rebase(0x3df8) 00:0000│ 0x555555557df8 (_DYNAMIC) ◂— 1 01:0008│ 0x555555557e00 (_DYNAMIC+8) ◂— 0x29 /* ')' */ 02:0010│ 0x555555557e08 (_DYNAMIC+16) ◂— 0xc /* '\x0c' */ 03:0018│ 0x555555557e10 (_DYNAMIC+24) ◂— 0x1000 04:0020│ 0x555555557e18 (_DYNAMIC+32) ◂— 0xd /* '\r' */ 05:0028│ 0x555555557e20 (_DYNAMIC+40) ◂— 0x11f0 06:0030│ 0x555555557e28 (_DYNAMIC+48) ◂— 0x19 07:0038│ 0x555555557e30 (_DYNAMIC+56) ◂— 0x3de8
got.plt[0]:指向与动态链接有关的数据(比如_DYNAMIC或内部标记),方便动态链接器定位动态段;got.plt[1]:指向link_map结构体,里面存着当前进程已加载模块的信息,是_dl_runtime_resolve的一个参数;struct link_map= 动态链接器内部用来描述“一个已加载 ELF 模块”的大结构体。
每加载一个可执行文件或.so,动态链接器就为它建一个link_map节点,把这些节点串成双向链表。每个
link_map对应一个 已加载的 ELF 对象:- 主程序;
- 每一个共享库
.so; - 甚至
ld-linux.so自己。
所有
link_map用l_next/l_prev串成链表,表头通过r_debug.r_map这个结构给调试器用。动态链接器做任何“找符号 / 找重定位 / 找依赖库”的事,基本都是从某个
link_map *开始,顺着里面的各种字段找.dynamic、符号表、重定位表等等。
glibc 内部的
link_map结构大致如下:1
2
3
4
5
6
7struct link_map {
ElfW(Addr) l_addr; // 该对象在内存中的基址偏移(load bias)
char *l_name; // 这个对象对应的文件路径
ElfW(Dyn) *l_ld; // 指向该对象的 .dynamic 段
struct link_map *l_next, *l_prev; // 链表指针
/* 后面一大堆是 glibc 内部字段 */
};l_addr- 作用:这个模块的 load bias / 基址。
- 含义:内存装载地址和 ELF 文件里 p_vaddr / e_entry 之间的差值。
- 对 PIE/共享库来说:地址 =
l_addr + 文件里写的虚拟地址。 - 动态链接器/调试器都用它来把“ELF 里的地址”映射成“进程里的真实地址”。
l_name- 模块的文件名(绝对路径),比如
/lib/x86_64-linux-gnu/libc.so.6。 dlopen/gdb info sharedlibrary之类都能看到它。
- 模块的文件名(绝对路径),比如
l_ld指向这个模块的
.dynamic段在内存中的位置(ElfW(Dyn) *)。.dynamic里面就是各种DT_*:DT_SYMTAB/DT_STRTAB/DT_HASH/DT_GNU_HASHDT_RELA/DT_JMPREL(.rela.dyn / .rela.plt 的信息)DT_NEEDED/DT_RPATH/DT_RUNPATH等等。
动态链接器初始化
link_map的时候,会扫l_ld指向的.dynamic,把有用的信息抄到下面的l_info[]里。
l_next/l_prev- 把所有
link_map串成一个双向链表。 - 链表表头在
struct r_debug.r_map里,DT_DEBUG会指向_r_debug,所以调试器可以从这里遍历所有已加载模块。
- 把所有
其中最重要的字段是
l_info:1
ElfW(Dyn) *l_info[DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM];
意思是:
把
.dynamic里各种 DT_* 项按照不同 tag 分类,
预先按索引塞进l_info[],方便 O(1) 拿到各种关键指针。例如(伪代码):
l_info[DT_SYMTAB]→ 指向.dynsym;l_info[DT_STRTAB]→ 指向.dynstr;l_info[DT_JMPREL]→ 指向.rela.plt;l_info[DT_PLTRELSZ]→.rela.plt的大小;l_info[DT_RELA]/DT_RELASZ→.rela.dyn;- …
这样
_dl_fixup/_dl_relocate_object在处理一个模块时,只要有link_map *l,就能很快拿到它的动态符号表、字符串表、重定位表等信息,而不用每次手动遍历.dynamic段。往下还有很多字段(
l_searchlist、l_runpath_dirs、l_dev/l_ino、l_versions、l_scope、l_mach等),大致用途:- 依赖关系和符号查找 scope;
- RPATH / RUNPATH 搜索路径;
- 版本信息(
VERSYM/VERDEF); - 这个模块是主程序 / 依赖库 /
dlopen动态加载; - 是否已经做过重定位、是否调用过
DT_INIT等; - 机器相关数据(
l_mach); - 最近一次符号查找缓存(
l_lookup_cache)。
这些对写漏洞利用 / ELF 分析来说一般不必全记死,知道“动态链接器有一张很大的状态表,
link_map是核心入口”就够了。典的懒绑定流程里(你前面那种
.plt+_dl_runtime_resolve)大致是:程序调用
foo@plt;foo@plt先jmp [foo@GOT],第一次会跳到push index; jmp PLT0;PLT0 调
_dl_runtime_resolve(或某个架构专用的 trampoline);_dl_runtime_resolve/_dl_fixup需要知道:- 是“哪个模块”发起的这次 PLT 调用(主程序?某个
.so?); - 以及这个模块的
.dynsym、.dynstr、.rela.plt等的地址。
- 是“哪个模块”发起的这次 PLT 调用(主程序?某个
这里就用到了 GOT:
按 System V / glibc 的传统约定:
- **
GOT[1](或.got.plt[1])里放的是当前模块的struct link_map ***; GOT[2]里放的是_dl_runtime_resolve的地址。
- **
这样
_dl_runtime_resolve就能:1
2
3
4
5
6// 伪代码(实际是汇编转 C 的逻辑)
struct link_map *l = (struct link_map *) got[1];
ElfW(Sym) *symtab = (ElfW(Sym) *) l->l_info[DT_SYMTAB]->d_un.d_ptr;
const char *strtab = (char *) l->l_info[DT_STRTAB]->d_un.d_ptr;
ElfW(Rela) *jmprel = (ElfW(Rela) *) l->l_info[DT_JMPREL]->d_un.d_ptr;
// 用 index 去 jmprel / symtab / strtab 里找符号、修 GOT 槽位……也就是说:
GOT[1] = 这个 PLT 所属模块的“身份证”;
从link_map *出发,动态链接器才能知道:
“我要在谁的.dynsym/.dynstr/.rela.plt里给谁修重定位。”got.plt[2]:保存_dl_runtime_resolve或对应入口桩的地址,PLT0 会通过这里跳进动态链接器。
精确含义依 ABI / glibc 版本略有差异,但结论统一:
.got.plt的前几项留给动态链接器实现 lazy binding,后面的槽位才是每个外部函数自己的 GOT entry。
PLT 表(.plt/.plt.got/.plt.sec)
PLT 是一堆小函数,每个外部符号(尤其是导入函数)在 PLT 里对应一个入口:
printf@pltgetenv@pltbar@plt- …
编译器/链接器不会生成:
1 | call printf ; 绝对或直接相对 |
而是生成:
1 | call printf@plt ; 调用当前模块里的 PLT stub |
PLT stub 内部再去看 GOT 条目:
- 运行时动态链接器填 GOT;
- PLT 通过 GOT 间接跳到真正的函数实现。
以 x86‑64 延迟绑定 PLT 为例,在未开启 FULL RELRO + lazy binding 时,PLT 表可以抽象成:
PLT0(通用入口):
1
2
3PLT0:
push *(GOT+8) ; 压 link_map 等信息
jmp *(GOT+16) ; 跳到 _dl_runtime_resolve对某个函数
bar的bar@plt:1
2
3
4bar@plt:
jmp *(bar@GOT) ; 通过 .got.plt[bar_index] 间接跳转
push n ; n = 对应重定位条目的索引
jmp PLT0 ; 交给 PLT0 / 动态链接器处理
第一次调用 bar 时:
bar@GOT槽位里放的是“跳回 PLT stub 后半段”的地址;jmp *(bar@GOT)实际跳到push n; jmp PLT0;PLT0 调
_dl_runtime_resolve,动态链接器:- 在
.dynsym、.dynstr、.gnu.hash等里查 “bar”; - 在
.rela.plt里找对应重定位; - 解析出真正的
bar地址,写进bar@GOT槽位; - 然后跳到真正的
bar。
- 在
后续调用 bar:
bar@GOT已经是正确地址;jmp *(bar@GOT)直接跳到真正的bar,不再走动态链接器;- 实现了 lazy binding:按需解析,第一次慢、之后快。
延迟绑定能成立的前提:
.got.plt对动态链接器是 可写 的。
除了 .plt 外,现代二进制(PIE + Full RELRO + CET)里,会同时存在:
.plt.plt.got.plt.sec
这不是三种“完全不同的机制”,而是 同一套机制在安全强化 & 兼容性约束下演化出来的不同分工。
.plt:是为 老式懒绑定协议 准备的入口;在 Full RELRO + BIND_NOW 下,一般不会实用,只是保留兼容。.plt.got:少量特殊函数的 PLT,是专门给个别函数(如__cxa_finalize)做一个 PLT 入口;这些函数在初始化/终结阶段有特殊要求,动态链接器可能在不同时间点处理;形式通常是:1
2
3
4__cxa_finalize@plt:
endbr64
bnd jmp *__cxa_finalize@GOTPCREL(%rip)
nop为什么单独放
.plt.got?
主要是布局和实现约定的问题:让动态链接器容易找到并提前处理,属于 ABI/x86_64 glibc 的细节。.plt.sec:现代“主力 PLT”,一般的 stub 模式(Full RELRO + CET)类似:
1 | foo@plt: |
与老 PLT 相比:
没有
push index; jmp PLT0这半截;调用路径就是单一步“间接跳转到 GOT 里记录的地址”;
结合 Full RELRO +
-z now:- 启动时动态链接器就把
.rela.plt的所有重定位做完; - 把
.got.plt槽位全部写成最终函数地址; - 然后把 GOT 页标记为只读;
- 之后
foo@plt就是一个固定的endbr64; jmp [GOT],不再发生 lazy binding。
- 启动时动态链接器就把
动态链接过程
动态链接器自举
在 ELF 格式的程序中,如果启用了动态链接(即不是 -static 编译),那么程序的启动流程会先进入动态链接器(如 64 位系统上的 /lib64/ld-linux-x86-64.so.2)。但由于动态链接器本身也是一个 ELF 可执行体,它也有重定位需求,必须先完成自我重定位才能开始为主程序服务,这一过程称为自举(Bootstrap)。
动态链接器的入口地址就是自举代码的起点,当内核将控制权交给动态链接器时,它会执行如下步骤:
- 读取自己的 GOT 表,通常通过
.got.plt区段定位。 - GOT 的第一个表项通常保存
.dynamic段的偏移,由此定位到.dynamic。 - 从
.dynamic段中解析出链接器自身的重定位表、符号表、字符串表等信息。 - 使用这些表项,对链接器自身的重定位表进行修复(如
R_*_RELATIVE条目),完成自身地址修正。
只有完成这些步骤后,链接器本身的全局变量、函数指针、跳转表等才能正常使用。这也意味着:动态链接器前半段的代码几乎不依赖任何已初始化的全局数据区,只能使用硬编码和偏移量操作。
装载共享对象
完成自举后,链接器会开始处理主程序(即用户编写的可执行文件)的依赖项。
- 合并全局符号表
链接器将主程序与链接器自身的符号表合并为一个全局符号表,供后续查找使用。 - 解析 DT_NEEDED
主程序的.dynamic段中包含多个DT_NEEDED项,每个表示一个需要加载的共享对象(动态库)。 - 构建装载集合
链接器将所有DT_NEEDED项依次加入待装载队列,并按一定顺序加载这些库。这个过程可以类比为对 ELF 依赖图的遍历,glibc 中使用的是广度优先遍历(BFS),可以避免较深的递归加载导致顺序不一致。 - 递归解析依赖
如果某个库又依赖其他共享对象(即它自身也有DT_NEEDED),链接器将其依赖也加入集合中,直到整个依赖树完全加载。 - 映射 ELF 文件
每个共享对象被打开后,链接器读取其 ELF 头部、程序头表(Program Header Table),将其.text、.data、.rodata等段通过mmap映射到进程地址空间中。
重定位和初始化
共享对象装载完成后,链接器执行重定位操作,将指针类符号修正为实际加载地址。
由于需要将多个模块装载到内存中,因此动态链接难免会有地址冲突问题,这就需要我们在加载的时候将模块中的相关地址修改为正确的值,这就是装载时重定位。
Linux和GCC支持这种装载时重定位的方法,在产生共享对象时,使用了两个GCC参数
-shared和-fPIC,如果只使用-shared,那么输出的共享对象就是使用装载时重定位的方法。
这包括 .got、.got.plt、全局变量等。常见重定位类型(以 x86 为例)有:
R_386_RELATIVE:重定位静态地址引用,如static int *p = &a;R_386_GLOB_DAT:全局变量地址写入.got表R_386_JUMP_SLOT:函数符号重定位,写入.got.plt,用于延迟绑定
为了提高程序启动速度,PLT(Procedure Linkage Table)+ GOT 机制支持懒绑定:首次调用外部函数时,PLT 入口跳转至 _dl_runtime_resolve,动态链接器在该函数中完成真正地址解析并修复 .got.plt 表项。
把同一个模块装到不同虚拟地址,如果在代码里写死了绝对地址,就需要修改代码段里的指令(所谓“对 .text 做重定位”),这会让代码页变成私有页,无法在多个进程间共享,也拉低启动性能。
用 地址无关代码(PIC)把“和绝对地址相关的东西”挪到数据表里就可以解决上述问题:
- 代码中的控制流(
call/jmp)尽量用相对位移;- 代码若要取“某个符号的绝对地址”,就先去 GOT(全局偏移表) 拿该符号当前进程里的真实地址,再访问;
- 调外部函数用 PLT(过程链接表):
call foo@plt→ PLT 查/填 GOT → 真正跳到函数。首次调用解析,之后命中 GOT(延迟绑定)。此时模块内与模块间
模块内控制流:天然 PC‑relative,对同一模块内的符号,用“相对当前指令的偏移”寻址(不依赖装载基址),无需表项。
注:x86‑64 上 RIP 是顺序下一条指令的地址(fall‑through),PC‑relative 以它为基准计算偏移。
模块内数据:
static/hidden:直接 RIP‑relative;- 默认可见全局:为支持 ELF 符号截获语义,经 GOT 间接。
模块间:
- 函数:PLT+GOT(支持延迟绑定);
- 数据:通过 GOT 间接;若主程序是非 PIE而直接引用共享库变量,可能触发 Copy relocation(启动时把值拷贝一份到主程序的
.bss)。
可通过环境变量 LD_BIND_NOW=1 禁用懒绑定,强制所有 JUMP_SLOT 重定位在程序启动时立即完成。
执行构造函数
重定位完成后,链接器将调用每个共享对象中注册的初始化函数:
.init_array:现代构造函数表,按数组顺序依次调用,优先使用。.init:旧式单入口构造函数(被_init调用)。.ctors:废弃机制,仅供兼容。
这些构造函数用于初始化 C++ 的全局对象、线程局部变量、资源连接等。
注意
**动态链接器不会主动执行主程序的 .init 和 .init_array**,这部分由程序自己的入口代码(通常是 __libc_csu_init)负责调用。
当所有依赖库装载完毕、重定位完成、构造函数执行完毕之后,动态链接器的工作完成,它将控制权移交给主程序入口,即 ELF 文件头 e_entry 指定的位置。在 glibc 中,这个流程是:
1 | _start |
至此,用户代码才真正开始执行。
提示
当程序执行结束时,还会依次执行 .fini_array、.fini 中注册的析构函数,以销毁全局对象、关闭连接、释放资源等。
动态链接器也会负责调用所有共享对象的 .fini_array,而主程序自身的 .fini_array 同样由 __libc_csu_fini 负责。
延迟绑定
在使用动态链接的程序里,模块之间常常存在大量的函数调用(而为了降低耦合,跨模块的可写全局变量一般较少)。如果在程序启动时就把所有外部函数的地址都解析并重定位完,会带来不必要的启动开销——毕竟很多函数在一次运行中从未被调用。因此,ELF/ld.so 采用延迟绑定:仅在函数第一次被调用时,才进行符号查找与对应 GOT 表的修补;未被用到的函数不会提前绑定,从而缩短启动时间,特别适合依赖众多库、外部调用巨量的程序。
只对“函数调用”可延迟。 变量(数据)引用的动态重定位一般在装载时一次性完成,不会延迟绑定。通过
dlopen()也能强制“立即(NOW)”或“延迟(LAZY)”解析,但“延迟”只适用于函数。
大多数系统/构建默认启用懒绑定(除非显式要求“立即绑定”)。可以用环境变量 LD_BIND_NOW=1 或链接选项 -Wl,-z,now 禁用懒绑定,改为装载时就解析全部外部函数。
与 RELRO 的关系:
Partial RELRO:仅将一部分动态链接数据区标记为只读,保留
.got.plt可写以支持懒绑定。Full RELRO:要求在进入
main前全部解析函数符号并把 GOT(含.got.plt)设为只读,这就事实上禁用了延迟绑定(等价于-z now)。代价是启动时多做一点工作,换来运行期更强的防篡改性。当然特殊情况也有在开启 FULL RELRO 的时候进行重定位,比如 ret2dlresolve 。
我们以调用 puts 函数为例讲解一下延迟绑定的过程。
首先第一次调用 puts 时由于 puts@got 没有进行重定位,因此会调用 _dl_runtime_resolve 函数进行重定位,_dl_runtime_resolve 函数将查找到的 puts 函数地址填写到 puts@got 后会调用 puts 函数。
**第一次调用 puts**(尚未解析):
调用点发出
call puts@PLT,跳到该函数的 PLT 入口(每个外部函数有自己的pltN)。进入
puts@plt后(典型两段式):1
2
3
4
5
6
7
8
9
10
11; --- 通用 PLT0 桩 ---
plt0:
push qword ptr [rip + .got.plt + 8] ; = .got.plt[1] => link_map
jmp qword ptr [rip + .got.plt + 16] ; = .got.plt[2] => 解析器入口
; --- 单个函数的专属 PLT 桩(俗称 pltN)---
; label: puts@plt
puts@plt:
jmp qword ptr [rip + puts@GOTPLT] ; 已解析:直接跳真实 puts
push dword ptr idx_puts ; 首调:压入 .rela.plt 的表项序号
jmp plt0 ; 进入通用桩由于
puts@GOTPLT被初始化成指回本桩的第二条指令(也可理解为“一个 PLT 局部小跳板”)。因此第 ① 步并不会离开本桩,而是落到后面的push $idx。这个idx就是该函数在.rela.plt里的表项序号。PLT0 从 GOT 中取到当前模块的
link_map,再跳转到运行时解析器(dl_runtime_resolve族)入口。.got.plt(函数用 GOT)前 3 个条目是保留位,后续每个条目对应一个可延迟解析的函数。
.got.plt[0]→_DYNAMIC的链接时地址
给动态链接器(ld.so)做“自举/定位”的锚点:它能让 ld.so 通过_DYNAMIC找到该对象的.dynamic段,进而读到DT_PLTGOT、DT_JMPREL、DT_SYMTAB、DT_STRTAB等指针,用来完成 PLT/GOT 的修补、符号解析等工作。这个槽不直接参与一次函数调用的跳转,但对装载期和解析期的元数据定位很重要。.got.plt[1]→ 当前对象的“描述符”(link_map指针)
这是传给解析桩的第一个参数。首调时,PLT 桩会把.got.plt[1]压栈/放寄存器,ld.so 由此拿到当前 ELF 对象的 **link_map**,再根据link_map->l_info[DT_*]找到.rela.plt/.rel.plt、.dynsym、.dynstr等表去解析符号、写回真实地址。.got.plt[2]→ 解析器入口(resolver trampoline)
这是 PLT0 要jmp去的目标(也就是_dl_runtime_resolve的汇编桩入口;在 glibc 上常见别名如_dl_runtime_resolve_xsave[_c])。PLT0 把上一步准备好的参数(link_map+ 重定位索引)“交给”这个解析桩,解析桩再调用 C 例程_dl_fixup完成R_X86_64_JUMP_SLOT的解析与回填.got.plt[n],并尾调用到真实函数。
解析器依据
link_map查.dynsym/.dynstr和 **.rela.plt**(注意:x86‑64 使用Elf64_Rela,即 RELA 形式),通过重定位条目的r_info找到目标符号,按动态链接的搜索顺序解析出真实地址。解析器把真实地址写回该函数的 GOT 槽(
.got.plt的对应项),随后跳转到puts真身继续执行。
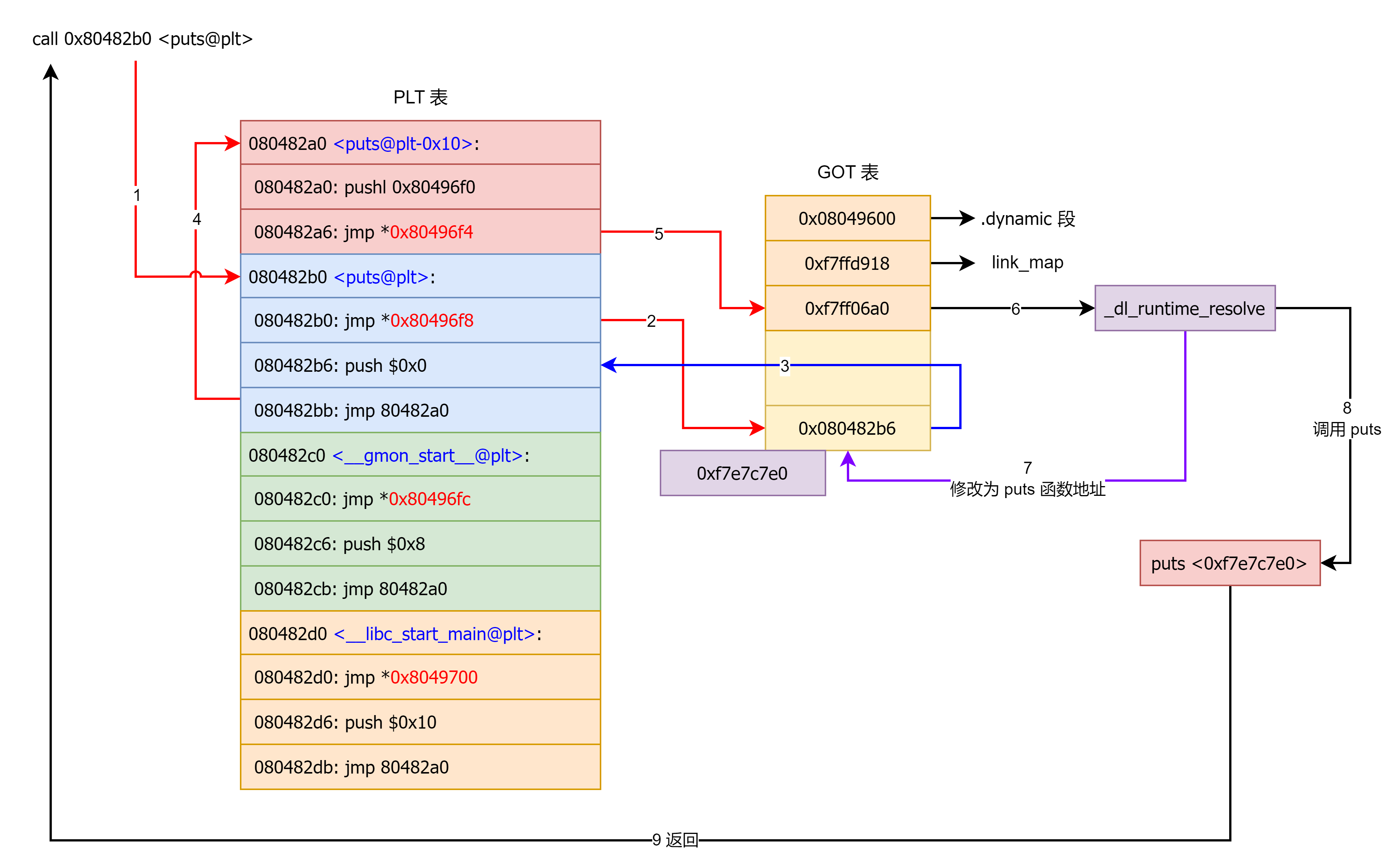
再次调用 puts,puts@PLT 直接从 puts@GOTPLT 读取已解析好的函数地址并跳转,不再进入解析器,因此热路径只有一次间接跳转开销。
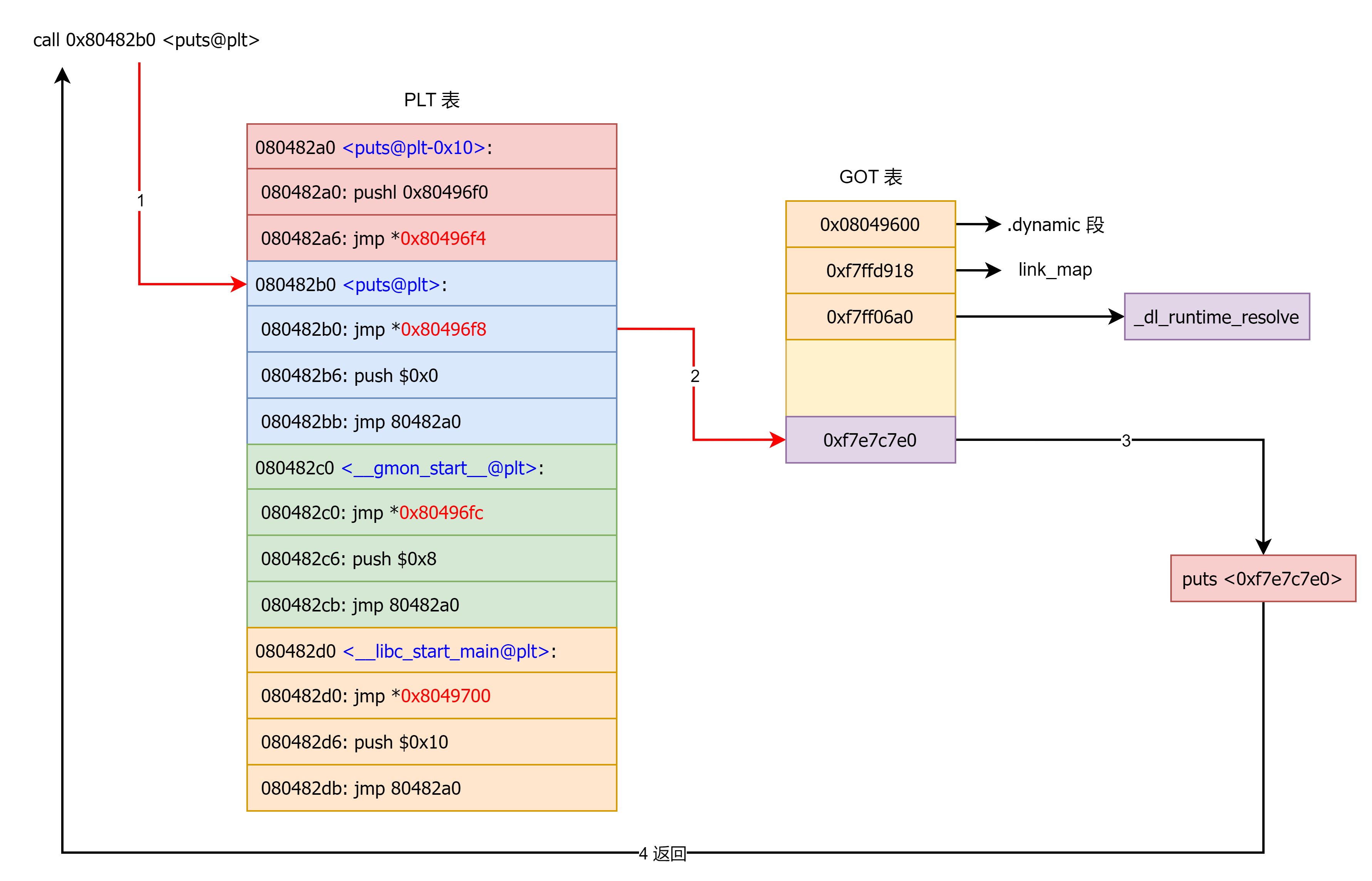
其中在第一次调用 puts 函数时调用的 _dl_runtime_resolve 函数的具体实现为:
- 用第一个参数
link_map访问.dynamic,取出.dynstr,.dynsym,.rel.plt的指针。 .rel.plt + 第二个参数求出当前函数的重定位表项Elf32_Rel的指针,记作rel。rel->r_info >> 8作为.dynsym的下标,求出当前函数的符号表项Elf32_Sym的指针,记作sym。.dynstr + sym->st_name得出符号名字符串指针。- 在动态链接库查找这个函数的地址,并且把地址赋值给
*rel->r_offset,即 GOT 表。 - 调用这个函数。
把
puts@GOTPLT改成指向printf@plt的第二条指令(也就是它的push idx_printf):
- 调用
puts@PLT→ 第一条jmp [rip+puts@GOTPLT]会跳到printf@plt的 fallback。printf@plt的 fallback 会push idx_printf; jmp plt0,于是解析器拿到的idx是printf的。_dl_fixup解析printf,并把真实printf地址写回.rela.plt[idx_printf].r_offset指向的槽(即 **printf@GOTPLT)——不是puts@GOTPLT**。- 你的
puts@GOTPLT仍然指向printf@plt的 fallback;以后每次puts@PLT都会“借道 printf 的 fallback”,解析器会很快认出已解析过,再尾调用真实printf。结论:这种劫持让
puts()实际上调用了printf(),且解析器修改的是printf的 GOT 槽,与“你最初跳出来的那个 GOT 槽”无关。
main 函数之外的启动 / 退出流程
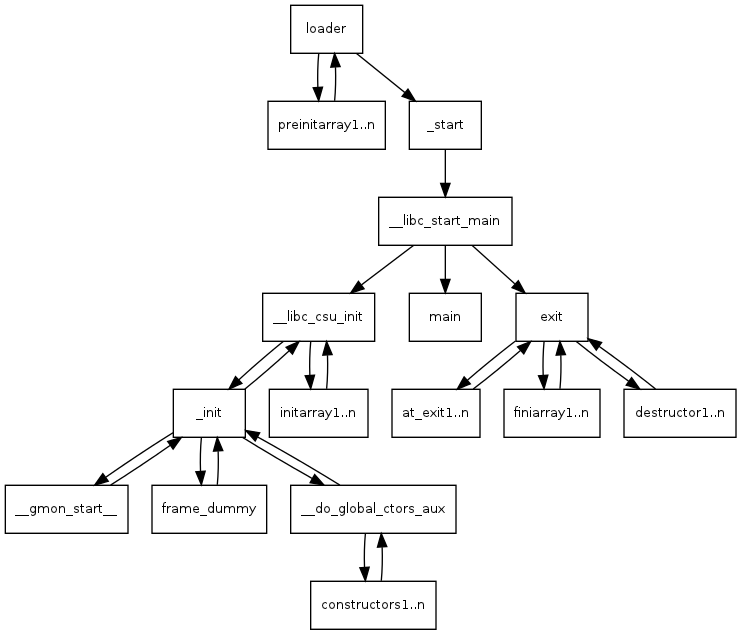
入口 _start
对静态可执行文件,入口就是你编译出来的 _start。
对动态可执行文件,入口其实是 **动态链接器的 _start**(ld-linux*.so 里的 _dl_start / _dl_start_user),它先完成自身装载、重定位,再跳进程序的 _start。
_start 通常来自 glibc 提供的 crt1.o,是 ELF 的真正入口。它主要做三件事:
从当前栈布局里取出 **
argc、argv、envp**;按 System V ABI 要求对齐栈(x86‑64 要求 16 字节对齐);
把
main、argc/argv、构造/析构函数入口等打包好,调用:1
__libc_start_main(main, argc, argv, init, fini, rtld_fini, stack_end);
x86‑64 的 _start 伪代码大致是:
1 | _start: |
__libc_start_main 初始化 + 调 main
在 glibc 的 csu/libc-start.c 里,__libc_start_main(或内部别名 generic_start_main)大致长这样:
1 | int LIBC_START_MAIN( |
ubp_av实际上就是argv,后面紧跟envp和auxv等;init、fini通常是__libc_csu_init/__libc_csu_fini;rtld_fini对动态程序是_dl_fini,对静态程序为NULL。
LSB 规范对 __libc_start_main() 的概述是:
“完成必要的运行环境初始化,调用
main,并在main返回后调用exit。”
__libc_start_main 在不同版本 glibc 实现细节略有出入,但核心套路非常稳定:
保存 argc/argv/envp:
- 解析
ubp_av,得到argc、argv、envp; - 设置全局
__environ = envp。
- 解析
处理 AUXV(辅助向量):
- 从栈上的 auxv 读取
AT_PHDR/AT_PHENT/AT_PHNUM、AT_ENTRY、AT_BASE、AT_PAGESZ等; - 对应字段保存在内部全局,例如
dl_phdr、dl_phnum,作为后续 TLS / 安全机制 / 堆栈检查等的输入。
- 从栈上的 auxv 读取
安全/环境相关初始化:
- 基于
geteuid/getuid、getegid/getgid设置_libc_enable_secure(判断是否 setuid/setgid); - 初始化
__stack_chk_guard、pointer_guard等保护值,用于栈溢出检测和函数指针混淆(PTR_MANGLE/DEMANGLE)。
- 基于
CPU / TLS / 线程等底层初始化:
ARCH_INIT_CPU_FEATURES:探测 CPU 指令集能力(SSE/AVX 等)并缓存到*_cpu_features;__libc_setup_tls():搭 TLS 模板,初始化 TLS 相关数据;__pthread_initialize_minimal():初始化极简线程环境,为后面的 pthread 函数调用铺路。
注册退出回调:
- 如果
rtld_fini != NULL(动态链接程序),调用__cxa_atexit(rtld_fini, ...)注册成退出时的回调(典型就是_dl_fini); - 后面还会把
fini(__libc_csu_fini)通过__cxa_atexit注册为退出回调——这些最终都会在exit()路径里被__run_exit_handlers调用。
- 如果
调用
init(通常是__libc_csu_init):- 负责调用
.preinit_array/_init/.init_array里的构造函数。
- 负责调用
调用
main并处理返回:1
2int result = main(argc, argv, envp);
exit(result);exit最终会进入__run_exit_handlers()。
__libc_csu_init 构造函数调用
__libc_csu_init 实现位于 glibc csu/elf-init.c,大致逻辑是:
1 | void __libc_csu_init (int argc, char **argv, char **envp) |
因此构造函数调用顺序为:
.preinit_array(静态程序为主);.init(通常是_init);.init_array(C++ 静态对象构造函数等)。
退出路径:exit
exit 定义在 glibc 的 stdlib/exit.c 里,大致长这样(删掉了一堆属性宏和弱符号):
1 | void exit (int status) |
也就是说:
exit()自己什么都不做,直接把活交给__run_exit_handlers,最后由后者调用_exit真正终止进程。
__run_exit_handlers() 核心函数在 stdlib/exit.c 中:
1 | static void |
主要做:
调 TLS 析构函数(线程本地析构链);
走一遍
__exit_funcs链表,按注册顺序反向调用:on_exit()注册的回调;atexit()注册的回调;__cxa_atexit()注册的 C++ 析构函数(包括_dl_fini、__libc_csu_fini等);
在新版本中,通过弱符号调用
_IO_cleanup(即 FSOP 中常见的那个点);最后调用
_exit(status),直接陷入内核终止进程(_exit是系统调用封装,并不是你原文里的“status &= 0xff; abort()那种伪代码)。
exit(int status):C 标准库函数(声明在<stdlib.h>)
➜ 做“正常退出”:调用各种析构函数 /atexit回调、刷新 stdio 缓冲区、做库级清理,最后再调用_exit。
_exit(int status):POSIX 系统调用封装(声明在<unistd.h>)
➜ 直接让内核结束进程,不跑 C 库的清理逻辑,不调用atexit、不刷新 stdio 缓冲、也不跑 C++ 析构这类用户态收尾。GNU libc 手册直接说得很白:
_exit是exit用来终止进程的原始原语;它不会调用atexit/on_exit的回调。所以
exit()= “**先跑所有用户态清理,再调用_exit**”。
TLS 析构链:__call_tls_dtors + tls_dtor_list
在 __run_exit_handlers() 一开始(且 run_dtors == true),会调用 TLS 析构链:
1 | if (run_dtors) |
__call_tls_dtors 实现位于 libc/cxa_thread_atexit_impl.c:
1 | typedef void (*dtor_func)(void *); |
要点:
tls_dtor_list是 线程局部变量(__thread),每个线程有一条析构链;func经过PTR_DEMANGLE解密,混淆密钥来自pointer_guard(通常在 TLS/TCB 中);- 每个节点销毁后
free掉,且减少对应link_map->l_tls_dtor_count。
想用 TLS dtor 劫持控制流,需要:
- 能伪造一条
tls_dtor_list(可控func/obj/next); - 且能泄露
pointer_guard,绕过PTR_DEMANGLE。
这是一些 TLS‑dtor 利用中常用的路径。
__exit_funcs:atexit/on_exit/__cxa_atexit
__run_exit_handlers 的主体循环维护一个 exit_function_list 链表,结构在 stdlib/exit.c 附近定义:
1 | struct exit_function { |
__run_exit_handlers 会:
1 | while (*listp != NULL) { |
从最后一个
exit_function_list开始,倒序遍历fns[--idx];根据
flavor决定调用:ef_on:func.on.fn(status, arg)(对应on_exit);ef_at:func.at()(对应atexit);ef_cxa:func.cxa.fn(arg, status)(对应__cxa_atexit,也会被标记成ef_free防止重复调用);
调用前会用
PTR_DEMANGLE对函数指针做一次解混淆;遍历完一个节点后,移动到
listp = cur->next,并释放旧节点(最后一个静态节点不会 free)。
要点:
- 所有用户通过
atexit、on_exit、__cxa_atexit注册的函数,最终都挂在这个链表上; - 每个
exit_function_list里有 32 个槽,填满后再链入一个新节点; - 调用顺序:后注册的先调用(栈式 LIFO);
- 调用前,同样用
PTR_DEMANGLE对函数指针解混淆。
如果你能:
- 泄露
pointer_guard(绕过PTR_DEMANGLE),并且 - 写入
exit_function_list.fns[]中的函数指针 / 参数,
就可以在正常 exit() 路径上拿到一个可控的 call 机会。很多人把 _dl_fini、__libc_csu_fini 这类系统级 handler 也统称为 “exit hook”(广义)。
动态程序的 _dl_fini
对于 动态链接程序(动态 libc + ld-linux.so) 来说,__run_exit_handlers 还会在合适的时机调用 动态链接器 的 _dl_fini():它同样是通过 __cxa_atexit 在 ld.so 启动阶段注册进去的。
动态链接程序的
_dl_fini是怎么挂进来的?在进程启动时,
__libc_start_main会把一些“需要在 exit 时调用的函数”通过__cxa_atexit注册到__exit_funcs里,其中对动态程序来说,**rtld_fini就是动态链接器的_dl_fini**:
2
3
4
5
6
if (rtld_fini != NULL)
__cxa_atexit ((void (*)(void *)) rtld_fini, NULL, NULL);
/* 对动态链接程序:rtld_fini == &_dl_fini */
/* 对纯静态程序:rtld_fini == NULL */于是当你
exit()时,__run_exit_handlers会在一堆 exit handler 里 **调用_dl_fini()**,进入动态链接器的清理逻辑。这就是为什么_dl_fini处在“正常退出路径”上。
_dl_fini 定义在 elf/dl-fini.c,简化后大致逻辑:
1 | // 省略了有关 SHARED 的处理逻辑 |
只要 _dl_fini 被调,__rtld_lock_lock_recursive / __rtld_lock_unlock_recursive 就一定会被执行,而且是成对调用。
1 | /* elf/dl-fini.c 片段,注释简化 */ |
宏展开后分别为:
1 | _rtld_local._dl_rtld_lock_recursive(&(_rtld_local._dl_load_lock).mutex) |
_rtld_global._dl_rtld_lock_recursive / _rtld_global._dl_rtld_unlock_recursive 是动态链接器用来给自己“封装锁操作”的两根函数指针,位于 ld.so 上。如果能改这些函数指针,那么就是狭义的 exit hook。
GL(dl_ns)[ns]._ns_loaded 是一个 link_map 链表,描述当前命名空间中加载的所有 ELF 模块(主程序、本地 .so、依赖 .so 等);每个 link_map 里有:
l_addr:模块加载基址;l_info[]:所有DT_*动态段条目的指针(包括DT_FINI_ARRAY、DT_FINI等);l_next:下一个模块。
_dl_fini 会按依赖排序后,对每个模块调用:
.fini_array里的析构函数数组;.fini(老式方式)。
具体过程为:按 maps[0..nmaps-1] 顺序调用 _dl_call_fini(map),真正执行析构,_dl_call_fini 会根据 l_info[DT_FINI_ARRAY] / l_info[DT_FINI] 找到 .fini_array 和 .fini,依次调用这些函数指针。
如果能伪造一个“假 link_map”,让 _dl_fini 在退出时遍历到它,就可以控制它调用哪一组 fini;这就是很多文章里提到的 House of Banana / _dl_fini 利用 的大致思路。
静态程序的 __libc_csu_fini
完全静态链接的 ELF(-static),不再依赖 ld-linux.so,因此没有 _dl_fini 这条路径。此时:
- 链接时传给
__libc_start_main的fini,是__libc_csu_fini(在csu/elf-init.c一带); - 它会通过
__cxa_atexit(fini, ...)被注册进__exit_funcs链表; - 在
exit()路径里,被当作一个普通的ef_cxaslot 调用。
__libc_csu_fini 的逻辑(略化)大概是:
1 | void |
因此对静态程序,想在正常退出路径上劫持流,常见手段是覆盖 .fini_array 里的函数指针(或构造 fake .fini_array 对应的内存)。
__libc_atexit 区段与 _IO_cleanup(FSOP)
在 __run_exit_handlers() 的最后,如果 run_list_atexit == true,会执行一个额外的 hook:
1 | /* stdlib/exit.c 中的关键逻辑 */ |
RUN_HOOK 宏的展开类似于:
1 | // 伪代码,实际宏用 start/stop 符号 |
也就是:
遍历
__libc_atexit段中的所有函数指针,逐个调用,直到遇到段尾。
其中一个经典条目就是 _IO_cleanup(定义在 libio/genops.c):
1 | /* libio/genops.c 关键逻辑(简化) */ |
动态链接程序:
pwndbg> u 0x7ffff7c4552c ► 0x7ffff7c4552c <__run_exit_handlers+412> lea rbx, [rip + 0x1d14c5] RBX => 0x7ffff7e169f8 (__elf_set___libc_atexit_element__IO_cleanup__) —▸ 0x7ffff7c8eb50 (_IO_cleanup) ◂— endbr64 0x7ffff7c45533 <__run_exit_handlers+419> lea r12, [rip + 0x1d14c6] R12 => 0x7ffff7e16a00 (_IO_helper_jumps) ◂— 0 0x7ffff7c4553a <__run_exit_handlers+426> cmp rbx, r12 0x7ffff7c4553d <__run_exit_handlers+429> jae __run_exit_handlers+443 <__run_exit_handlers+443> 0x7ffff7c4553f <__run_exit_handlers+431> nop 0x7ffff7c45540 <__run_exit_handlers+432> call qword ptr [rbx] 0x7ffff7c45542 <__run_exit_handlers+434> add rbx, 8 0x7ffff7c45546 <__run_exit_handlers+438> cmp rbx, r12 0x7ffff7c45549 <__run_exit_handlers+441> jb __run_exit_handlers+432 <__run_exit_handlers+432> 0x7ffff7c4554b <__run_exit_handlers+443> mov edi, ebp 0x7ffff7c4554d <__run_exit_handlers+445> call _exit <_exit> pwndbg> telescope 0x7ffff7e169f8 00:0000│ 0x7ffff7e169f8 (__elf_set___libc_atexit_element__IO_cleanup__) —▸ 0x7ffff7c8eb50 (_IO_cleanup) ◂— endbr64 01:0008│ 0x7ffff7e16a00 (_IO_helper_jumps) ◂— 0 02:0010│ 0x7ffff7e16a08 (_IO_helper_jumps+8) ◂— 0 03:0018│ 0x7ffff7e16a10 (_IO_helper_jumps+16) —▸ 0x7ffff7c8e730 (_IO_default_finish) ◂— endbr64 04:0020│ 0x7ffff7e16a18 (_IO_helper_jumps+24) —▸ 0x7ffff7c72260 (_IO_helper_overflow) ◂— endbr64 05:0028│ 0x7ffff7e16a20 (_IO_helper_jumps+32) —▸ 0x7ffff7c8dd50 (_IO_default_underflow) ◂— endbr64 06:0030│ 0x7ffff7e16a28 (_IO_helper_jumps+40) —▸ 0x7ffff7c8dd60 (_IO_default_uflow) ◂— endbr64 07:0038│ 0x7ffff7e16a30 (_IO_helper_jumps+48) —▸ 0x7ffff7c8f280 (_IO_default_pbackfail) ◂— endbr64
__libc_atexit段位于libc.so映像中;- GDB 里常见
__elf_set___libc_atexit_element__IO_cleanup__这一符号指向_IO_cleanup。
静态链接程序:
pwndbg> u 0x40aa7e ► 0x40aa7e <__run_exit_handlers+446> mov rbx, __elf_set___libc_atexit_element__IO_cleanup__ RBX => 0x4ca288 (__elf_set___libc_atexit_element__IO_cleanup__) 0x40aa85 <__run_exit_handlers+453> mov r12, 0x4ca290 R12 => 0x4ca290 0x40aa8c <__run_exit_handlers+460> cmp rbx, r12 0x40aa8f <__run_exit_handlers+463> jae __run_exit_handlers+483 <__run_exit_handlers+483> 0x40aa91 <__run_exit_handlers+465> nop dword ptr [rax] 0x40aa98 <__run_exit_handlers+472> call qword ptr [rbx] 0x40aa9a <__run_exit_handlers+474> add rbx, 8 0x40aa9e <__run_exit_handlers+478> cmp rbx, r12 0x40aaa1 <__run_exit_handlers+481> jb __run_exit_handlers+472 <__run_exit_handlers+472> 0x40aaa3 <__run_exit_handlers+483> mov edi, ebp 0x40aaa5 <__run_exit_handlers+485> call _exit <_exit> pwndbg> telescope 0x4ca288 00:0000│ 0x4ca288 (__elf_set___libc_atexit_element__IO_cleanup__) —▸ 0x413450 (_IO_cleanup) ◂— endbr64 01:0008│ 0x4ca290 ◂— 0 ... ↓ 5 skipped 07:0038│ 0x4ca2c0 (object) ◂— 0xffffffffffffffff
- 整个 libc 被链接进主程序,
__libc_atexit段是可执行文件里的一个节; - 一样会在
exit()路径上调用_IO_cleanup。
- 整个 libc 被链接进主程序,
_IO_cleanup 调 _IO_flush_all_lockp,后者会遍历 _IO_list_all 链表上的所有 FILE 对象,并对每一个调用 vtable 中的某些函数(如 __overflow、_IO_FILE_jumps 中的函数)。
1 | /* libio/genops.c 里,关键逻辑大致如下 */ |
这里有几个重要点:
遍历入口:
从_IO_list_all开始,逐个走_chain字段:1
for (fp = (_IO_FILE *)_IO_list_all; fp; fp = fp->_chain) { ... }
触发路径:
想要走到_IO_OVERFLOW(fp, EOF),需要满足一系列 flag / 指针条件:_flags没有_IO_NO_WRITES/_IO_ERR_SEEN;_flags包含_IO_CURRENTLY_PUTTING(说明是输出模式);_IO_write_ptr > _IO_write_base(说明缓冲区里“看起来有待写的数据”)。
这些值在 FSOP 里一般由你伪造 FILE 时手动布置。
**关键调用
_IO_OVERFLOW**:_IO_OVERFLOW(fp, EOF)本质是通过 vtable 的间接调用:1
2
3
4
5/* libio/libioP.h 中类似宏定义 */
vtable 里长这样:
1
2
3
4
5
6struct _IO_jump_t {
JUMP_FIELD (size_t, __dummy);
JUMP_FIELD (size_t, __dummy2);
JUMP_FIELD (int, __overflow); /* 就是这里被 _IO_OVERFLOW 用 */
/* 后面还有一堆函数指针:__underflow、__xsputn 等等 */
};所以
_IO_OVERFLOW(fp, EOF)其实就是:1
fp->vtable->__overflow(fp, EOF);
这就是 FSOP 最关键的“可控函数指针调用”。
_IO_list_all 是一个全局指针,指向所有活动 FILE 结构组成的链表(实际上是 _IO_FILE_plus):
1 | /* libio/libioP.h 里类似这样的定义 */ |
链表通过 file._chain 字段串起来:
1 | struct _IO_FILE { |
如果你能:
- 控制
_IO_list_all,让它指向你伪造的FILE结构; - 控制
vtable或利用_IO_str_jumps等特性;
就可以在 exit() 阶段,通过 _IO_cleanup → _IO_flush_all_lockp → vtable 调用,拿到可控 PC。这就是 FSOP 攻击的经典路径。
共享库
共享库版本
共享库版本命名
在 ELF 系统(Linux 等)中,共享库通常采用如下“约定俗成”的命名方式:
前缀:
lib中间:库名 +
.so后缀:一串用点分隔的数字版本号,一般为 3 段:主版本号(MAJOR)、次版本号(MINOR)、发布号(RELEASE)
实际上并不是强制必须是 3 段数字,有些库只有两段,或者采用略有差异的规则,但含义类似。
主版本号(Major)
表示 ABI 发生不兼容变更 的重大升级(接口删除、参数类型改变、语义改变等)。
不同主版本号之间通常视为 不兼容。
升级主版本号时:
- 依赖旧主版本的程序需要修改、重新编译;或者
- 系统同时保留多个主版本的共享库(例如
libfoo.so.1和libfoo.so.2并存),老程序继续用旧版本。
次版本号(Minor)
- 表示 增量升级:在保持已有接口不变的前提下,新增加一些接口符号。
- 主版本号相同的前提下,高次版本号向后兼容低次版本号。
- 程序只要不使用“新加的符号”,通常可以在较旧次版本的库上运行。
发布号(Release / Patch)
- 表示 bug 修复、性能优化等,不新增接口,也不修改接口。
- 相同主版本号和次版本号下,不同发布号之间一般视为 完全兼容。
- 依赖某个
MAJOR.MINOR的程序,可以在任意MAJOR.MINOR.x上正常运行。
glibc(C 标准库)和动态链接器本身的命名规则稍有历史遗留问题,不完全符合上面“libname.so.MAJOR.MINOR.RELEASE”的形式。
以 64 位 glibc 为例:
真实文件:
libc-2.31.soSO-NAME:
libc.so.6库路径示例:
2
lrwxrwxrwx 1 root root 12 Apr 7 2022 /lib/x86_64-linux-gnu/libc.so.6 -> libc-2.31.so可以看到:
- 真实文件名不是
libc.so.6.0.0这种形式,而是libc-2.31.so;- 但 SO-NAME 仍然遵循“libname.so.MAJOR” 的形式(
libc.so.6),ABI 规则依然是“主版本号变更才视为不兼容”。不同发行版上,
libc.so.6有时是符号链接,有时也可能是直接的 ELF 文件实现,这属于实现细节,理解为“SO-NAME 对应的那个对象”即可。动态链接器(ld-linux)命名也比较特殊,同样是历史和兼容性原因导致的特殊命名方式。例如:
2
lrwxrwxrwx 1 root root 32 Apr 7 2022 /lib64/ld-linux-x86-64.so.2 -> /lib/x86_64-linux-gnu/ld-2.31.so
- 真实文件是
ld-2.31.so;- 对外暴露的名字为
ld-linux-x86-64.so.2;
SO-NAME
通常一个共享库会同时存在三个“层次”的名字(很多资料只提其中两种,容易混淆):
真实文件名(Real name)
比如:1
/lib/libfoo.so.2.6.1
这是实际存放在磁盘上的文件,带有完整的版本号。
SO-NAME(soname)
这是 ABI 级别的名字,用来标识“接口版本”,一般只包含主版本号:1
libfoo.so.2
- 由链接器在生成共享库时写入 ELF 文件的
.dynamic段中的DT_SONAME条目。 - 编译、链接可执行文件时,链接器会把库的 SO-NAME 写入可执行文件的
.dynamic段中的DT_NEEDED条目(注意是DT_NEEDED,不是DT_NEED)。
- 由链接器在生成共享库时写入 ELF 文件的
链接名(linker name)
仅用于编译/链接阶段,一般是不带版本号的:1
libfoo.so
- 当你在命令行写
-lfoo时,链接器会去找libfoo.so(以及静态库libfoo.a),决定与哪个库链接。 - 这个名字通常由开发包(
-dev/-devel包)提供为指向 SO-NAME 的符号链接。
- 当你在命令行写
典型目录结构示例(省略了路径前缀):
1 | libfoo.so -> libfoo.so.2 # 链接名(编译时用) |
系统会在库所在目录为共享库创建一个以 SO-NAME 为名的软链接,指向真实文件,例如:
1 | $ ls -l /lib/x86_64-linux-gnu/libc.so.6 |
- 可执行文件中记录的是
DT_NEEDED = "libfoo.so.2"这样的 SO-NAME,而不是libfoo.so.2.6.1。 - 动态链接器(
ld-linux-*)在加载程序时,会按照搜索路径在各个共享库目录(/lib、/usr/lib等)中查找 名字为 SO-NAME 的文件,最后会被软链接引导到真正的文件。
这样做的好处:
程序只绑定到 SO-NAME,不依赖完整版本号;
升级库时,只需要:
- 替换真实文件(例如安装
libfoo.so.2.7.0), - 把
libfoo.so.2软链接指向新文件, - 不改变 SO-NAME(仍然是
libfoo.so.2),就可以在同一 ABI 下实现平滑升级。
- 替换真实文件(例如安装
Linux 提供 ldconfig 工具来维护这些软链接和缓存,安装或更新共享库后通常会运行 ldconfig:
扫描默认共享库目录(如
/lib、/usr/lib以及配置中的其他目录);ldconfig会读取/etc/ld.so.conf和/etc/ld.so.conf.d/目录下的一些.conf文件,得到一堆“库目录列表”;在这些目录里扫描所有的lib*.so*文件;一般 Linux 发行版在装 glibc / 基础系统包的时候,会顺手:
- 创建
/etc/ld.so.conf; - 在
/etc/ld.so.conf.d/目录下放一些.conf文件。
比如典型的
/etc/ld.so.conf:1
include /etc/ld.so.conf.d/*.conf
意思是:
“真正的配置都丢在
/etc/ld.so.conf.d/目录里,我把它们全 include 进来。”而
/etc/ld.so.conf.d/里头的那些.conf文件,通常是各个软件包自己扔的,例如:glibc 自己放一个,写多架构相关目录:
1
2
3
4/lib/x86_64-linux-gnu
/usr/lib/x86_64-linux-gnu
/lib32
/usr/lib32某些第三方包(数据库、GPU 驱动、音视频 SDK 等)安装时放一个:
1
2/opt/myvendor/lib
/opt/myvendor/lib64
- 创建
自动为库创建或更新 SO-NAME 软链接;
更新
/etc/ld.so.cache中的动态链接库缓存,加速查找。
当你执行:
1 | sudo ldconfig |
ldconfig 会做的事之一:在每个库目录里,帮你维护“SO-NAME → 真文件”的软链接。
例如目录里有一个真实库文件:
1 | /usr/lib/x86_64-linux-gnu/libfoo.so.2.6.1 |
这个 ELF 的 .dynamic 段里 DT_SONAME 写着:libfoo.so.2。
那 ldconfig 会确保存在一个软链接:
1 | /usr/lib/x86_64-linux-gnu/libfoo.so.2 -> libfoo.so.2.6.1 |
这样,当程序的 DT_NEEDED 里写的是 libfoo.so.2 时,动态链接器只需要按这个名字查文件,就能通过软链接跳到对应的真实版本。
ldconfig 还会生成 /etc/ld.so.cache,这一步是为了提速。没有缓存的话,每次程序启动,动态链接器都得:
- 遍历它认为的所有库目录(可能十几个);
- 一路找 “有没有名叫
libfoo.so.2的文件”。
这会比较慢,所以引入了一个全局缓存文件 /etc/ld.so.cache:
它是个二进制文件,里边就是一堆类似:
1
2
3libfoo.so.2 -> /usr/lib/x86_64-linux-gnu/libfoo.so.2
libc.so.6 -> /lib/x86_64-linux-gnu/libc.so.6
...格式专门设计成“方便二进制查找”的结构。
ldconfig 就是负责:
- 根据
ld.so.conf+ 默认目录扫描所有库; - 把“库名 → 路径”的映射写入
/etc/ld.so.cache。
之后每次启动程序时,ld.so 都会先在 /etc/ld.so.cache 里查库名:
- 找到了:直接去对应路径
open; - 找不到:再去默认目录
/lib、/usr/lib里挨个遍历。
符号版本
仅用 SO-NAME 管理依赖仍然存在一个经典问题:
程序在某个系统上编译链接时,使用的是 较新的次版本号的共享库,而运行时所在系统的库虽然 SO-NAME 一样,但次版本号较低,缺少某些新加的符号,导致运行失败。
例如:
- 编译时链接的是
libfoo.so.2.6.1(其中新增了foo_new_api符号); - 可执行文件中记录的是
DT_NEEDED = "libfoo.so.2"; - 在目标系统上只装有比较老的
libfoo.so.2.3.0,没有foo_new_api; - 运行时动态链接器在解析
foo_new_api时找不到对应符号,会报错。
这个问题就是所谓的 次版本号交会问题(Minor‑revision Rendezvous Problem)。SO-NAME 只区分主版本号,无法精细到“符号级别”的兼容关系。
为了解决上述问题,并允许库在 不改 SO-NAME 的前提下进行复杂演进,现代 ELF 系统引入了 符号版本机制:
每个导出符号(函数、全局变量)除了名字外,还关联一个 版本标签,类似于:
1
2
3printf@@GLIBC_2.2.5
memcpy@@GLIBC_2.2.5
memcpy@GLIBC_2.14对同名符号,可以同时存在多个版本(老版本保留,新版本新增),通过版本标签区分。
可执行文件在链接时,会把“自己实际使用的那个符号版本”记录下来:
老程序继续引用老版本的符号;
新程序可以链接到新版本的符号;
运行时动态链接器根据符号名 + 版本号精确匹配,从而保证:
- 老程序不会突然跑到新符号语义上去;
- 新程序不会错误地绑定到旧符号上。
在 ELF 文件中,符号版本信息主要通过几类条目配合实现:
.dynamic段中有:DT_VERSYM:指向.gnu.version表;DT_VERDEF/DT_VERNEED:分别描述本库 定义 的符号版本以及 依赖 的其他库的符号版本信息。
.gnu.version(由DT_VERSYM指向):- 与动态符号表
.dynsym一一对应; - 为每个符号提供一个“版本索引”。
- 与动态符号表

动态链接器大致流程:
- 读取可执行文件或共享库的
.dynsym、.gnu.version、.gnu.version_r等信息,知道每个导入符号需要哪个版本; - 在目标共享库中查找具有匹配“名字 + 版本”的导出符号;
- 找不到合适版本就报“undefined symbol: xxx@VERSION”之类的错误。
符号版本机制允许库在保持相同 SO-NAME 的前提下,同时保留旧符号版本,实现非常精细的 ABI 兼容策略,较好地缓解了“次版本号交会问题”:
- 程序依赖的是某个具体版本的符号;
- 系统只要提供该版本(或兼容版本),程序就能正常运行。
共享库系统路径
FHS(Filesystem Hierarchy Standard)是 Linux/Unix 系统的文件层次结构标准,大致规定了:
- 哪些目录由发行版管理(
/bin、/lib、/usr等); - 哪些目录留给本地管理员(
/usr/local); - 第三方软件大致放在哪(
/opt)。
共享库路径也遵守这个思想:越基础、越“引导级别”的库,越靠近根目录;越高层应用,越往 /usr / /usr/local 走。
glibc 的动态链接器把某些路径视为 受信任目录,典型就是
/lib、/usr/lib以及其多架构子目录(/lib/x86_64-linux-gnu等)。在 secure‑execution 模式(例如执行 setuid/setgid 程序)下,动态链接器会:
- 忽略一些环境变量(如
LD_LIBRARY_PATH、LD_PRELOAD等);- 只从受信任目录中加载库,避免被非特权用户通过环境污染劫持。
/lib 系列:系统引导和最基础运行环境
/lib 放置系统 引导和最小用户态环境 所必需的共享库,例如 libc.so.*、ld-linux*.so.*、某些基础加密 / 压缩库等。
系统要求在根文件系统刚挂载好时,就必须能访问这些库;即使 /usr 单独挂载,也要确保系统能先起来。
现代多架构系统上,/lib 往往只是入口,还会细分为:
/lib/x86_64-linux-gnu/lib/i386-linux-gnu/lib/x32-linux-gnu/lib64(在部分发行版上是主 64 位库目录)
这是所谓 Multiarch(多架构)布局:同一系统里可以并存多种 ABI 的同名库(如 32/64 位两个 libc.so.6)。
/usr/lib 系列:发行版自带的“普通软件库”
/usr/lib 存放包管理器安装的绝大多数共享库,例如 GUI 框架、网络库、数据库驱动、多媒体库等。
常见路径有:
/usr/lib/x86_64-linux-gnu/usr/lib/i386-linux-gnu- 部分发行版上的
/usr/lib32、/usr/lib64等。
与 /lib 作区分,可以简单理解为:
“系统刚活过来时就必须要的库在
/lib;能晚点再用的库在/usr/lib。”
/usr/local/lib 系列:本地安装的软件库
从源码 ./configure && make && make install 默认前缀通常是 /usr/local,对应库就会装到:
/usr/local/lib/usr/local/lib/x86_64-linux-gnu等。
这样不覆盖 /usr/lib 里的系统库,可以同时存在“系统版 + 自己编译版”;
FHS 规定:发行版不要乱动
/usr/local,留给系统管理员自己折腾。
用户配合 /etc/ld.so.conf 或 LD_LIBRARY_PATH 可以方便地让程序优先使用 /usr/local/lib 下的库。
其他常见库路径:/lib32、/lib64、/opt/*/lib 等
不同发行版/架构上你还能看到:
/lib32//usr/lib32:64 位系统上存放 32 位兼容库(给 32 位程序用的libc.so.6等)。/lib64//usr/lib64:某些发行版中“所有 64 位库都放这里”,/lib//usr/lib留给 32 位。/opt/<vendor>/lib:第三方软件通常安装在/opt/vendor,库在/opt/vendor/lib或lib64。一般靠启动脚本设置LD_LIBRARY_PATH或 RPATH/RUNPATH 让程序找到这些库。
共享库查找过程
预加载阶段
预加载(preload) 指的是:在正常按依赖查找之前,强制先装载一批共享库,这些库里的符号可以覆盖后面加载的库,实现 hook 或注入。
glibc 文档明确写了预加载来源的优先顺序:
有多种方式可以指定预加载库,其处理顺序是:
- 环境变量
LD_PRELOAD- 直接调用动态链接器时使用
--preload参数- 配置文件
/etc/ld.so.preload
LD_PRELOAD(进程级预加载)
通过 LD_PRELOAD 环境变量指定预先加载的库。
该机制对设置了该环境变量的进程本身以及它 fork/exec 出来的子进程(环境变量默认是继承的)生效,且只对 使用 glibc 动态链接器的 ELF 动态链接程序 有效,并且 在 secure-execution 模式下会被严格限制。
对静态链接的可执行文件、不使用 ld.so 的程序、或者使用其他 C 库(如 musl 的 ld-musl)的程序无效。
LD_PRELOAD 列表中的每一项可以是:
- 带路径的名字(包含
/):如/home/me/mylib.so; - 不带路径的名字(纯库名):如
libmylib.so。
内容是一个共享库“列表”,用空格或冒号分隔,没有转义机制。
1 | # 单个库 |
没有转义语法是 ld.so 自己的规则:
The items of the list can be separated by spaces or colons,
and there is no support for escaping either separator.也就是说,在 动态链接器解析这根字符串时,它看到空格/冒号就认为那是分隔符,不存在像
\:、\"之类的“再转义”机制。
动态链接器对每一项做法是:
shell 层先展开动态字符串 token:
$ORIGIN:程序或共享对象所在目录;$LIB:当前架构对应的lib或lib64;$PLATFORM:处理器平台字符串,如"x86_64"。
例如:
1
2LD_PRELOAD='$ORIGIN/mylib.so' ./prog
LD_PRELOAD='/path/$LIB/libfoo.so'注意用单引号防止 shell 把
$ORIGIN当环境变量展开。**如果名字中含有
/**:按给出的相对或绝对路径直接尝试加载,找不到就报错
cannot be preloaded: ... ignored.。如果名字中不含
/(纯库名):按普通库查找顺序:
RPATH→LD_LIBRARY_PATH→RUNPATH→/etc/ld.so.cache→/lib/usr/lib等默认目录。
预加载库中如果定义了与 libc 等库同名的函数(如 open、malloc),在默认的符号查找规则下,这些定义会 优先 被绑定;
man page 对
LD_PRELOAD在 secure-execution 模式下的说明:
secure-exec 触发条件:
例如执行 setuid/setgid 程序、运行赋予 capability 的二进制等,内核会通过AT_SECURE标记通知 ld.so 进入“安全模式”。在 secure-exec 模式下:
LD_PRELOAD属于被“剥离”的环境变量之一:
- 对程序来说,它根本看不到
LD_PRELOAD;- ld.so 也不会按普通方式信任用户传入的库。
对预加载名单的额外限制:
- 列表里 包含
/的路径一律忽略(即不能指定任意路径);- 仅会从“标准搜索目录”(如
/lib、/usr/lib等)中预加载库,- 且被预加载的库必须自身带 set-user-ID 位——现实中几乎不会这么配置。
效果可以简单理解为:
对普通用户来说,想通过
LD_PRELOAD=自己写的.so去劫持 setuid 程序,基本是不可行的。
ld.so --preload(命令行预加载)
glibc 从 2.30 开始为动态链接器本身提供了 --preload 选项:
1 | # 手动调用动态链接器 + 指定预加载库 + 要运行的程序 |
选项形式:
--preload list其中
list的语法与LD_PRELOAD完全一致:- 使用空格或冒号分隔多个库;
- 支持
$ORIGIN/$LIB/$PLATFORM动态 token; - 同样没有“转义分隔符”的机制(分隔逻辑一样)。
和 LD_PRELOAD 的差异:
LD_PRELOAD是环境变量,默认会被子进程继承;--preload是这一次调用 ld.so 的命令行选项,只对这次执行生效,
不会自动影响子进程后续 exec 的新程序。
/etc/ld.so.preload(系统级预加载)
/etc/ld.so.preload 是由 root 管理的 系统级预加载列表文件。
- 内容:一个由 空白字符(空格 / 换行 / tab)分隔的共享库路径列表;
- 这些库会在每次加载任意程序时,由 ld.so 按顺序强制预加载;
- 它的处理顺序在
LD_PRELOAD和--preload之后。
同样地:
- 每一条目可以包含
$ORIGIN、$LIB、$PLATFORM等 token; - 每次新程序启动时,ld.so 都会重新读取这个文件;
- 修改文件只影响之后启动的进程,不会 retroactively 影响已在运行的进程。
多架构支持与 ELFCLASS 错误
在 64 位系统上,如果你在
/etc/ld.so.preload写了一个仅有 64 位版本的库:
对 64 位程序没问题;
但当 32 位程序启动时,同样会尝试预加载这库,结果就是:
典型的多架构写法是使用
$LIBtoken:
然后:
- 为 32 位架构在
/path/lib放libhook.so;- 为 64 位架构在
/path/lib64放libhook.so。这样:
- 32 位进程
$LIB → lib,加载/path/lib/libhook.so;- 64 位进程
$LIB → lib64,加载/path/lib64/libhook.so。与 secure‑execution / 容器 的关系
和
LD_PRELOAD不同:
/etc/ld.so.preload是 由 root 写入的系统配置文件;- 即使在 secure-execution 模式下,ld.so 也仍然会读取该文件(因为它假定 root 已经过滤过风险);
- 这也是为什么很多 rootkit / 攻击技术会使用
/etc/ld.so.preload做持久化代码注入。在容器 / sandbox 中还会遇到一个常见现象:
- 容器内的
/etc/ld.so.preload可能绑定宿主机的文件;- 但宿主机中提到的库路径并未挂到容器内;
- 结果就是容器里每次执行程序都会看到
cannot be preloaded: ignored的错误提示。
正常查找阶段
预加载阶段结束后,动态链接器才开始对每个 DT_NEEDED 的库名按规则查找。
以 glibc 的 ld.so 为例,它的搜索顺序(普通非 secure 模式下)大致是:
RPATH(
DT_RPATH)- 如果存在
DT_RPATH且没有DT_RUNPATH,先按DT_RPATH中的目录搜索; DT_RPATH是旧机制,在很多新程序中已被DT_RUNPATH取代。
- 如果存在
LD_LIBRARY_PATH环境变量- 由用户设置的、冒号分隔的目录列表;
- 在 setuid/setgid 等 secure‑execution 模式下会被忽略并从环境中剥离。
RUNPATH(
DT_RUNPATH)- 新机制,只影响“当前 ELF 直接依赖”的库;
- 适合作为“内嵌搜索路径”,优先级低于
LD_LIBRARY_PATH。
/etc/ld.so.cache(由ldconfig生成的缓存)- 一个二进制文件,内部是“库名 → 路径”的索引;
- 动态链接器会优先查这个缓存,加快查找速度。
受信任默认路径:
/lib、/usr/lib…- 如果缓存里没找到,就会在这些目录及其多架构子目录中遍历查找;
- 在使用
-z nodefaultlib链接的情况下,这一步可能被跳过(非常少见)。
特殊情况:DT_NEEDED 是绝对路径
- 如果
DT_NEEDED条目就是/opt/mylib/libfoo.so.2这种绝对路径,动态链接器会直接尝试加载这个路径; - 失败则报错,不会再去其它目录找;
- 可移植性很差,一般只在特化场景下使用。
对 setuid/setgid 程序,动态链接器会进入 secure‑execution 模式:
- 一大堆影响自身行为的环境变量被剥离(包括
LD_LIBRARY_PATH、LD_PRELOAD、LD_DEBUG等);- 只从受信任路径加载库,避免用户通过环境变量或非受信任目录劫持 setuid 程序。
更改共享库
Linux 系统提供了很多方法来改变动态链接器装载共享库路径的方法,通过使用这些方法,我们可以满足一些特殊的需求,比如共享库的调试和测试、应用程序级别的虚拟等。
LD_LIBRARY_PATH
在 Linux 系统中,LD_LIBRARY_PATH 是一个由若干个路径组成的环境变量,每个路径之间由冒号隔开。默认情况下, LD_LIBRARY_PATH 为空。如果我们为某个进程设置了 LD_LIBRARY_PATH ,那么进程在启动时,动态链接器在查找共享库时,会首先查找由 LD_LIBRARY_PATH 指定的目录。这个环境变量可以很方便地让我们测试新的共享库或使用非标准的共享库。
比如更换 libdl.so.2 和 libc.so.6 的 pwntools 脚本如下:
1 | sh = process("./lib/ld.so --preload libdl.so.2 ./pwnhub".split(), env={"LD_LIBRARY_PATH": "./lib/"}) |
LD_PRELOAD
系统中另外还有一个环境变量叫做 LD_PRELOAD ,这个文件中我们可以指定预先装载的一些共享库甚或是目标文件。在 LD_PRELOAD 里面指定的文件会在动态链接器按照固定规则搜索共享库之前装载,它比 LD_LIBRARY_PATH 里面所指定的目录中的共享库还要优先。无论程序是否依赖于它们,LD_PRELOAD 里面指定的共享库或目标文件都会被装载。
比如更换 libdl.so.2 和 libc.so.6 的 pwntools 脚本如下:
1 | process("./lib/ld.so ./pwnhub".split(), env={"LD_PRELOAD": "./lib/libc.so.6 ./lib/libdl.so.2"}) |
LD_DEBUG
另外还有一个非常有用的环境变量 LD_DEBUG ,这个变量可以打开动态链接器的调试功能,当我们设置这个变量时,动态链接器会在运行时打印出各种有用的信息,对于我们开发和调试共享库有很大的帮助。
例如运行 LD_DEBUG=files /bin/ls 命令时动态链接器打印出了整个装载过程,显示程序依赖于哪个共享库并且按照什么步骤装载和初始化,共享库装载时的地址等。
bindings:显示动态链接的符号绑定过程。libs:显示共享库的查找过程。versions:显示符号的版本依赖关系。reloc:显示重定位过程。symbols:显示符号表查找过程。statistics:显示动态链接过程中的各种统计信息。
patchelf
用于对于依赖不是很复杂的程序更换 libc ,有一下几点需要注意:
- 如果在漏洞利用时用到了动态链接相关结构最好不要 patchelf,因为 patchelf 会改变动态链接相关结构的位置。
- 一个程序在一个版本的虚拟机里面 patchelf 后换到另一个版本虚拟机中可能会运行失败。
- 在 patch 完 libc 后最好把 ld 也 patch 成大版本相同的 ld ,否则会运行失败。
修改 libc:
1 | patchelf --replace-needed libc.so.6 ./libc.so.6 ./pwn |
修改 ld:
1 | patchelf --set-interpreter ./ld-2.31.so ./pwn |
有的时候像 libm.so.6 换不过来的情况可能因为程序依赖的某个动态库本身也依赖该动态库:
➜ cursedst patchelf --replace-needed libm.so.6 ./libm.so.6 ./st
➜ cursedst ldd ./st
linux-vdso.so.1 (0x00007fffdfad9000)
./libstdc++.so.6 (0x000076ee89e00000)
./libgcc_s.so.1 (0x000076ee8a195000)
./libc.so.6 (0x000076ee89a00000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x000076ee8a09c000)
./ld-linux-x86-64.so.2 => /lib64/ld-linux-x86-64.so.2 (0x000076ee8a1c5000)
➜ cursedst patchelf --replace-needed libm.so.6 ./libm.so.6 ./st
patchelf --replace-needed libm.so.6 ./libm.so.6 ./libstdc++.so.6
➜ cursedst ./st
What's your name?
^C
➜ cursedst ldd ./st
linux-vdso.so.1 (0x00007ffc52bea000)
./libstdc++.so.6 (0x0000747ef3600000)
./libgcc_s.so.1 (0x0000747ef396a000)
./libc.so.6 (0x0000747ef3200000)
./libm.so.6 (0x0000747ef3512000)
./ld-linux-x86-64.so.2 => /lib64/ld-linux-x86-64.so.2 (0x0000747ef399a000)
进程线程
多线程与 TLS
TLS 基本概念
线程的访问非常自由,它可以访问进程内存里的所有数据,甚至包括其他线程的堆栈(如果它知道其他线程的堆栈地址,那么这就是很少见的情况),但实际运用中线程也拥有自己的私有存储空间,包括以下几方面:
- 栈(尽管并非完全无法被其他线程访问,但一般情况下仍然可以认为是私有的数据)。
- 线程局部存储(Thread Local Storage, TLS)。线程局部存储是某些操作系统为线程单独提供的私有空间,但通常只具有很有限的容量。
- 寄存器(包括PC寄存器),寄存器是执行流的基本数据,因此为线程私有。
实际上,线程私有的数据有:
- 局部变量
- 函数的参数
- TLS 数据
线程共享的数据有:
- 全局变量
- 堆上的数据
- 函数里的静态变量
- 程序代码,任何线程都有有权利读取并执行任何代码。
- 打开的文件,A 线程打开的文件可以由 B 线程读写。
TLS 数据
一个全局变量如果使用 __thread 关键字修饰,那么这个变量就变成线程私有的 TLS 数据,也就是说每个线程都在自己所属 TLS 中单独保存一份这个变量的副本。例如下面的代码中,a 和 b 都是 TLS 数据,而 c 是全局变量。
1 | // gcc test.c -o test -g -pthread |
分析生成的 ELF 文件的节表,发现多出了 .tdata 和 .tbss ,这两个节分别记录已初始化和未初始化的 TLS 数据。
其中 .tbss 在 ELF 文件中不占用空间, .tdata 在 ELF 中存储了初始化的数据,比如上面的代码中的 __thread uint32_t a = 0x114514 。
ELF 加载到内存中后, .tdata 和 .tbss 这两个节合并为一个段,在程序头表中这个段的 p_type 为 PT_TLS(7) 。
TLS 结构
在 ELF TLS ABI 的抽象模型中,每个线程大致有这么几层:
TCB(Thread Control Block)
TCB 是“线程指针(Thread Pointer, TP)”指向的那块结构。对 x86_64 来说,TP =
fs.base,即 FS 段基址。线程控制块头部包含指向 DTV 的指针、stack_guard、pointer_guard等。DTV(Dynamic Thread Vector)
一个数组
dtv_t[],用于“索引到各个模块的 TLS block”。TLS blocks
每个“有 TLS 的模块”对应一个 block,内部就是该模块
.tdata + .tbss的一个 per-thread 副本。对每个线程来说,这一套布局对应一块内存区域,专属于这个线程;1
[ .tdata 初值拷贝 ][ .tbss 区域(零填) ][ 可能还有对齐 padding ]
DTV 在 glibc 中定义如下:
1 | struct dtv_pointer { |
在 glibc 的布局里(注意指针是 dtv+1):
dtv[-1].counter:当前这块 dtv 的“容量”(最多可以容纳多少 modid);比如值是 64,就说明最多用dtv[1]..dtv[64]存放 TLS block 信息;dtv[0].counter:当前线程 DTV 的 TLS 版本号(generation);每当有dlopen/dlclose引入/移除带 TLS 的模块,全局的 generation 会变化;运行时可以通过它判断“当前这个线程的 DTV 是否需要更新/扩容”;dtv[i].pointer(i >= 1):表示 模块 ID 为 i 的模块 的 TLS block 信息:val:指向该线程中,这个模块 TLS block 起始;to_free:如果这个 block 是单独malloc出来的,to_free记录原始指针以便free;
如果这个 block 是静态 TLS 区的一部分(比如主程序 TLS),to_free就是NULL。
模块 ID(
modid)来自每个模块的link_map->l_tls_modid,是由动态链接器分配的,典型从1开始,主程序是 1,第一个共享库是 2,依次往后。
初始创建线程时,
allocate_dtv会按当前“最大 modid 值 + 冗余”分配一块 DTV;如果后面dlopen了新的带 TLS 的模块,dl_tls_max_dtv_idx变大,某些线程就需要扩容:
- 检查
dtv[-1].counter是否够用;- 不够的话重新
malloc一块更大的、拷贝旧的内容、更新 TCB 里的dtv指针;- 同时更新
dtv[0].counter为新的 generation 值。这也是为什么你会看到
_dl_allocate_tls_init里有一堆 “slotinfo_list / generation / max modid” 之类的逻辑:本质上就是管理这张 DTV 表的生命周期。
以 x86_64 glibc 为例,TCB 实际上就是 tcbhead_t,该类型定义在 sysdeps/x86_64/nptl/tls.h:
1 | typedef struct |
在 pwndbg 中可以通过 tls 命令查看当前线程的 TCB:
pwndbg> tls
Thread Local Storage (TLS) base: 0x7ffff7ee3800
TLS is located at:
0x7ffff7ee3000 0x7ffff7ee6000 rw-p 3000 0 [anon_7ffff7ee3]
Dumping the address:
tcbhead_t @ 0x7ffff7ee3800
0x00007ffff7ee3800 +0x0000 tcb : 0x7ffff7ee3800
0x00007ffff7ee3808 +0x0008 dtv : 0x7ffff7ee4220
0x00007ffff7ee3810 +0x0010 self : 0x7ffff7ee3800
0x00007ffff7ee3818 +0x0018 multiple_threads : 0x0
0x00007ffff7ee381c +0x001c gscope_flag : 0x0
0x00007ffff7ee3820 +0x0020 sysinfo : 0x0
0x00007ffff7ee3828 +0x0028 stack_guard : 0xea3da6237c5e9c00
0x00007ffff7ee3830 +0x0030 pointer_guard : 0xbe3ff50ef5f8b0d9
0x00007ffff7ee3838 +0x0038 unused_vgetcpu_cache : {0, 0}
0x00007ffff7ee3848 +0x0048 feature_1 : 0x0
0x00007ffff7ee384c +0x004c __glibc_unused1 : 0x0
0x00007ffff7ee3850 +0x0050 __private_tm : {0x0, 0x0, 0x0, 0x0}
0x00007ffff7ee3870 +0x0070 __private_ss : 0x0
0x00007ffff7ee3878 +0x0078 ssp_base : 0x0
0x00007ffff7ee3880 +0x0080 __glibc_unused2 : {{{
i = {0, 0, 0, 0}
[...]
Output truncated. Rerun with option -a to display the full output.
在线程里,FS base 指向的是一个 struct pthread,其首字段就是 tcbhead_t header;所以:
fs:0x00→header.tcbfs:0x08→header.dtvfs:0x28→stack_guardfs:0x30→pointer_guard
也就是说:每个线程的 TLS / canary / pointer_guard 都是挂在它自己的 FS base 下面的一整个结构里。
例如 __stack_chk_guard 这种 TLS 栈 canary 变量,最终就是通过 FS 相对偏移拿到 stack_guard;
TLS 初始化过程
主线程 TLS 初始化
前面提到过在 main 开始前会调用 __libc_setup_tls 初始化 TLS 。
在 __libc_setup_tls 函数中,首先会遍历 ELF 的程序头表,找到 p_type 为 PT_TLS(7) 的段,这个段中就存储着 TLS 的初始化数据。
1 | if (_dl_phdr != NULL) |
然后通过 sbrk 调用为 TLS 中的数据以及一个 pthread 结构体分配内存。其中 pthread 结构体的第一项为 tcbhead_t header; ,即前面提到的 TCB 。
1 | // 为 TLS block + TCB 预留空间 |
布局大致如下,其中 TLS_INIT_TCB_SIZE == sizeof(struct pthread)。
1 | [ TLS Block (静态 TLS) ][padding][ struct pthread (TCB) ] |
之后初始化 _dl_static_dtv ,也就是主线程的“静态 DTV 数组”,具体过程为:
1 | dtv_t _dl_static_dtv[2 + TLS_SLOTINFO_SURPLUS]; |
随后,通过 INSTALL_DTV 宏把 TCB 里的 dtv 指针指向 &_dl_static_dtv[1]:
dtv[-1] == _dl_static_dtv[0]→ 容量dtv[0] == _dl_static_dtv[1]→ generationdtv[1] == _dl_static_dtv[2]→ 主程序 TLS block 信息
然后将 TLS 的初始数据也就是 PT_TLS 段中的数据复制到 TLS 中。
此时 TLS 相关结构之间的关系如下图所示:
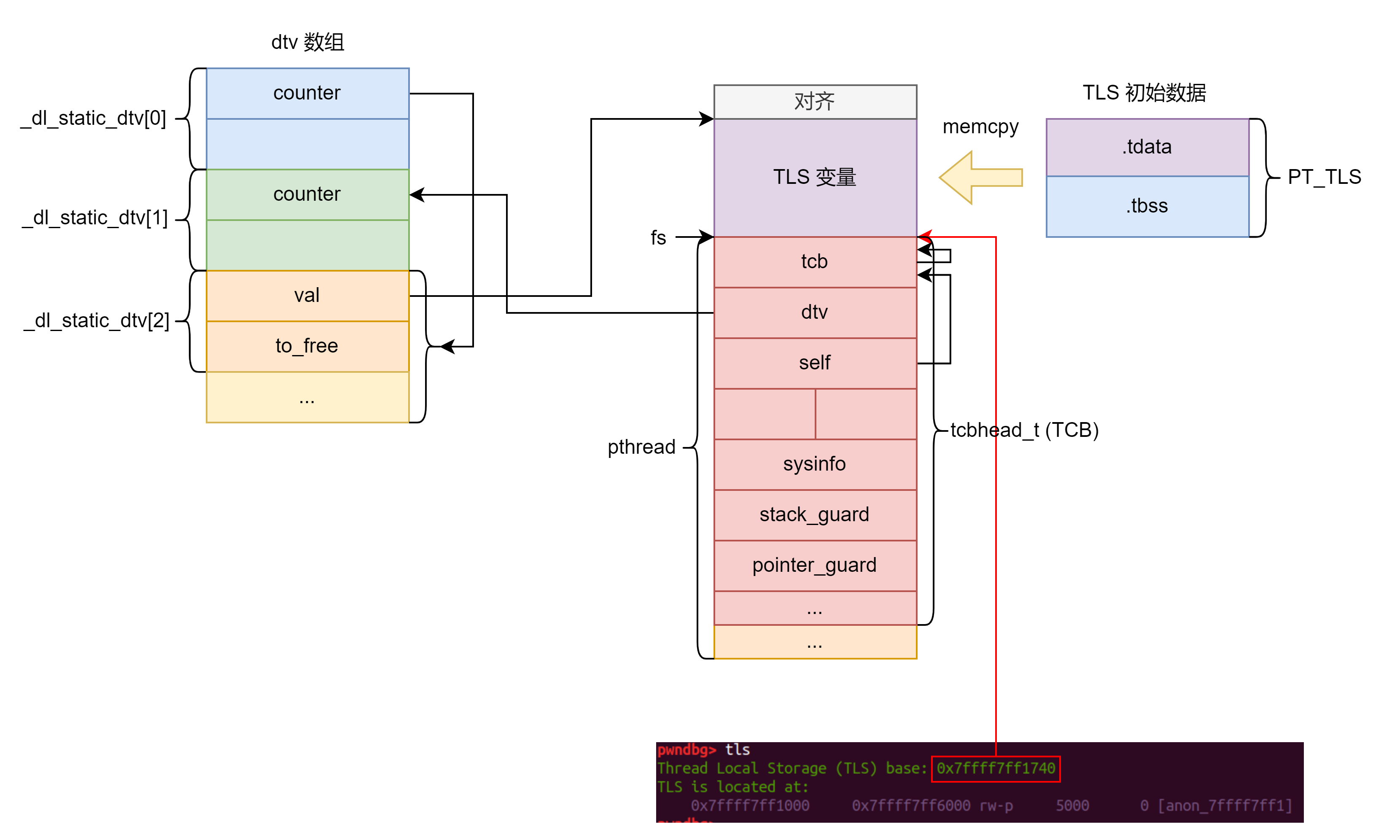
另外还会初始化 link_map 中的 TLS 相关的数据,由此我们可以知道 link_map 中这些字段的含义:
l_tls_offset:TCB 在 TLS 中的偏移。l_tls_align:TLS 初始数据的对齐,在 TLS 中 TLS 初始数据关于l_tls_align向上取整。l_tls_blocksize:TLS 初始数据的大小,也就是前面提到的 TLS Block 的大小。l_tls_initimage:TLS 初始数据的地址。也就是PT_TLS段的地址。l_tls_initimage_size:PT_TLS段在文件中的大小,也就是.tdata的大小。l_tls_modid:模块编号。
1 | struct link_map *main_map = GL(dl_ns)[LM_ID_BASE]._ns_loaded; |
创建线程时 TLS 初始化
创建线程的函数 pthread_create 实际调用的是 __pthread_create_2_1 函数,在该函数中调用了 allocate_stack 函数,展开为 allocate_stack:
1 |
|
allocate_stack 大致做几件事:
- 用
mmap分配一块“栈 + guard page”的内存; - 在栈顶附近摆一个
struct pthread(即 TCB+线程描述符),返回指针pd; - 调用
_dl_allocate_tls(TLS_TPADJ(pd))为这个新线程分配并初始化 TLS/DTV。
在 allocate_stack 函数中会调用 mmap 为线程分配栈空间,然后初始化栈底为一个 pthread 结构体并将指针 pd 指向该结构体。最后调用 _dl_allocate_tls 函数为 TCB 创建 dtv 数组。
1 | struct pthread *pd; |
_dl_allocate_tls 函数依次调用 allocate_dtv 和 _dl_allocate_tls_init 分配和初始化 dtv 数组。
1 | void * |
allocate_dtv 函数调用了 ptmalloc 堆管理器的 calloc 函数为 dtv 数组分配内存,初始化 dtv[0].counter 为数组中元素数量,并且让 pd->dtv 指向 dtv[1] 。
1 | /* 安装 dtv 指针。 |
_dl_allocate_tls_init 函数会遍历 dl_tls_dtv_slotinfo_list 中的 link_map ,初始化 dtv 数组并将初始数据复制到 TLS 变量中。从这里可以看出,如果一个模块有 TLS 变量,则该模块对应的 dtv->pointer.val 指向 TLS 变量的起始地址。
1 | /* 先将当前模块对应的 dtv 槽位标记为“未分配”。 |
回到 __pthread_create_2_1 函数,在完成了 pthread 的一系列初始化后调用了 THREAD_COPY_STACK_GUARD 和 THREAD_COPY_POINTER_GUARD 两个宏,这两个宏的展开如下:
1 | /* 拷贝当前线程的 stack_guard(栈 canary 种子)到新线程 pd->header.stack_guard */ |
不难看出这两个宏把当前线程(当前 fs 寄存器还没有指向新线程的 TCB)的 TLS 中的 stack_guard 和 pointer_guard 都复制到子线程的 TLS 的对应位置上。因此可以确定线程的 stack_guard 和 pointer_guard 与主线程相同。
最后需要确定是 fs 寄存器何时被修改,因为 fs 寄存器不能再用户态修改,因此一定是一个系统调用完成了对 fs 寄存器的修改。
通过调试发现,pthread_create->create_thread->clone 中的 clone 系统调用完成了对 fs 寄存器的修改。
gdb 调试技巧
多线程调试
线程信息
1 | (gdb) info threads # 或 i th |
典型输出(示意):
1 | Id Target Id Frame |
*前缀那一行是 当前线程。- 左边的
1,2,3是 GDB 自己的线程号(gdb thread id),跟 LWP/TID 不是一个东西。 - GDB 有个方便变量
$_thread,值就是当前线程的这个 gdb 线程号,可以在条件里用。
切换线程:
1 | (gdb) thread 3 # 切到 gdb 线程号 3 |
一次性把所有线程的栈打出来:
1 | (gdb) set pagination off # 建议放到 ~/.gdbinit |
断点技巧
按线程号下断点:
1 | (gdb) break worker.c:42 thread 3 |
条件断点:
1 | (gdb) break worker.c:42 if i > 1000 |
$_thread 是当前线程的 gdb 线程号,专门拿来做这种条件判断的。
你很多需求是:
跑的时候在某一行打印点东西,不要真正停下来。
这用 dprintf 最合适:
1 | # 在 foo.c:100 打印 i 和当前线程号,打印后自动继续 |
只对某个线程打印,用条件:
1 | (gdb) dprintf foo.c:100, "hit foo: i=%d, thread=%d\n", i, $_thread |
dprintf= 断点 + 打印 + 自动 continue。$bpnum是刚刚创建的这个断点的编号。
这个命令非常适合当作“动态 printf 调试”,不用改代码、不用 commands + continue 那一套。
在裸 gdb 里这么写没问题,但在 pwndbg 环境里,这个 continue 有可能把调试器锁死:
1 | break foo.c:100 |
pwndbg 规避写法:把 continue 换成 Python 的 gdb.execute("continue")
1 | break foo.c:100 |
这里的 pi 是 python-interactive 的缩写,相当于一行 Python:
1 | python |
这个写法就是你记得的那句:“在 pwndbg 的脚本里不能直接写 continue,要用个 python 语句”。
相关设置
all-stop vs non-stop —— “谁会被停下来”
2
(gdb) set non-stop onall-stop(默认):
任意一个线程因为断点 / 单步 / 信号停了,
👉 这个进程里的所有线程都一起停。non-stop:
每个线程独立:
某个线程 hit 断点,它停;
其他线程可以继续跑,不会自动一起停。这是“停的语义”:
- all-stop:一停全停;
- non-stop:谁撞断点,谁停,其它照跑。
scheduler-locking —— “从停恢复时,谁能继续跑”
scheduler-locking是另一个开关,只在你从断点继续/单步时起作用:
2
3
(gdb) set scheduler-locking on # 继续/单步时只让当前线程跑
(gdb) set scheduler-locking step # 单步时只当前线程跑,continue 时所有线程跑它不改变“谁会被停住”,只改变:
👉 “你敲
continue/next/step之后,哪些线程会动”。
多线程单步时常见场景:
在 2 号线程里
next,结果 3 号线程先跑了一堆,屏幕上全是别的线程的日志。
这时候用:
1 | (gdb) set scheduler-locking off # 默认:谁都能跑 |
一般推荐:
- 平时用默认
off; - 调某一个线程逻辑时·用
set scheduler-locking step,单步时不被其他线程抢。
注意:
如果当前线程卡在 pthread_mutex_lock,又设成 on,那真正持锁的线程永远不跑,整个程序就被你锁死了。
默认是 all-stop:一个线程停,全停。
non-stop 则允许某些线程停,其他线程继续:
1 | (gdb) set target-async on |
然后你可以:
1 | (gdb) thread 3 |
多进程调试
真多进程调试时基本靠四个东西:
set follow-fork-mode parent|childset detach-on-fork on|offset follow-exec-mode same|newcatch fork / catch exec
只跟父 or 只跟子:follow-fork-mode
1 | (gdb) set follow-fork-mode parent # 默认,跟父 |
例如:启动器 fork 出干活的 worker,你只想调 worker:
1 | (gdb) set follow-fork-mode child |
fork 后,gdb 会自动切到子进程继续调。
同时调父子:detach-on-fork off + 多 inferiors
想父子进程都在 gdb 手里:
1 | (gdb) set follow-fork-mode parent |
fork 之后:
1 | (gdb) info inferiors |
inferior N:切换当前进程;- 在每个 inferiors 里你还能
thread apply all bt。
不要某个进程了:
1 | (gdb) detach inferiors 2 # 放飞 2 号进程 |
处理 exec:follow-exec-mode
很多程序是:
父进程 fork 子进程 → 子进程
exec真正的程序。
follow-exec-mode 决定 exec 时 gdb 怎么处理当前 inferior:
1 | (gdb) set follow-exec-mode same # 默认 |
same:当前 inferior 直接变成新程序,之后run也跑新程序;new:exec 时新建一个 inferior,旧的还保留着旧程序的信息。
如果你就是冲着“fork 之后的那坨新程序”来的,一般组合是:
1 | set follow-fork-mode child |
精确卡在 fork / exec:catch
1 | (gdb) catch fork |
每次 fork / exec 时都会停一下,你可以立刻 bt 看是谁调用的。
一个经典例子:在 exec 之后的 main 上断:
1 | (gdb) set follow-fork-mode child |
这样即使一开始没新程序的符号,也能在 exec 后补断点。
常见保护
checksec 可以查看程序开启了哪些保护。
该命令通常对应两种:
通过
apt安装的checksec。pwntools安装时注册的一个 console_scripts entry point,不过需要root权限安装才能直接在命令行使用。
➜ ~ /usr/bin/checksec --file=/bin/ls
RELRO STACK CANARY NX PIE RPATH RUNPATH Symbols FORTIFY Fortified Fortifiable FILE
Full RELRO Canary found NX enabled PIE enabled No RPATH No RUNPATH No Symbols Yes 6 18 /bin/ls
➜ ~ /usr/local/bin/checksec /bin/ls
[*] '/bin/ls'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
FORTIFY: Enabled
SHSTK: Enabled
IBT: Enabled
RELRO(Relocation Read-Only)
传统 ELF 里有一块非常关键又非常危险的数据区:GOT(Global Offset Table,全局偏移表)。
- 程序调用外部函数(如
printf)时,会通过 PLT/GOT 间接跳转; - 如果攻击者能改写 GOT 表里的“函数地址”,就能把
printf改成system或直接跳到任意 gadget——典型的 GOT 覆写劫持控制流。
RELRO 的目的:
把运行时不需要再修改的重定位相关段(尤其是 GOT)在程序启动时就重定位完,然后改成只读,防止被写。
原理解释
链接时加 -Wl,-z,relro,ld 会在 ELF 里创建一个 PT_GNU_RELRO 程序头,对应一段内存区域,里面通常放:
.init_array/.fini_array/.jcr.dynamic.got和.got.plt的前几个 entry(具体和实现有关)
动态链接器加载完之后,会在完成对这些区域的重定位之后,对 PT_GNU_RELRO 覆盖的内存调用 mprotect(PROT_READ, …),也就是“把这块只读化”。这就是“Relocation Read-Only”的由来。
关键点:是 loader 在运行时
mprotect,而不是编译期就只读。否则启动时没法往 GOT /.init_array里写重定位结果。
编译选项
checksec 一般会显示三档:
No RELRO
- 编译/链接时使用
-Wl,-z,norelro,或者干脆没启用 relro(老工具链默认)。 .got和.got.plt以及.init_array/.fini_array所在的页都是普通RW数据段。
- 编译/链接时使用
Partial RELRO(部分 RELRO)
- 使用了
-Wl,-z,relro,但没配-Wl,-z,now; - loader 会把 非 PLT 部分的
.got放在PT_GNU_RELRO,完成重定位后将其设为只读;但.got.plt仍然可写,以便 lazy binding 时动态写入函数真实地址。 - 结果就是
.init_array/.fini_array等“析构/构造”数组被放到了只读区域;.got(非 PLT 部分)只读;但got.plt仍然可写;也就是说 Partial RELRO 仍然可以 GOT 覆写,只是“锁了一部分 GOT 和 init/fini 数组”。
- 使用了
Full RELRO(完全 RELRO)
- 同时使用
-Wl,-z,relro -Wl,-z,now;或者开启了-Wl,-z,now,在现代发行版中通常就会默认加上-z relro。 - Full RELRO 在 Partial 的基础上多做了两件事:
- 禁用 lazy binding:
-z now/BIND_NOW要求 loader 在程序启动时就解析所有导入符号,包括 PLT 的函数引用。 - 因为不再需要在运行时修改
.got.plt,所以 loader 可以在完成绑定后,把.got.plt也一起设成只读。
- 禁用 lazy binding:
.got+.got.plt全部在PT_GNU_RELRO段下,被mprotect成只读;.init_array/.fini_array等也同样只读;代价是:所有符号启动时就解析完,启动时间略有增加,所以很多库/程序为了启动性能只开 Partial。
- 同时使用
Stack Canary
Canary(Stack Smashing Protector,SSP) 是编译器插的一种防御机制,用来检测栈上的缓冲区溢出。
原理解释
Canary 保护的基本思路是在局部变量(特别是数组)和控制数据(saved RBP / 返回地址)之间插一个随机值,函数返回前检查这个值有没有被改,如果被改了就直接崩溃而不是正常 ret。
如果某个栈上的数组发生溢出,要想覆盖到返回地址,几乎必然要先踩到 canary。在函数返回时,如果 canary 被改动,就调用 __stack_chk_fail 直接终止程序。
GCC + glibc 的 SSP 逻辑(x86‑64)如下:
1 | push rbp |
pwndbg 中的 canary 命令可以查看 canary 的值以及在栈上存储的位置。
pwndbg> canary --help usage: canary [-h] [-a] Print out the current stack canary. options: -h, --help show this help message and exit -a, --all Print out stack canaries for all threads instead of the current thread only. pwndbg> canary AT_RANDOM = 0x7fffffffe3a9 # points to global canary seed value TLS Canary = 0x7ffff7ee3828 # address where canary is stored Canary = 0xc4049b4e3a9f4700 (may be incorrect on != glibc) Thread 1: Found valid canaries. 00:0000│ 0x7fffffffb528 ◂— 0xc4049b4e3a9f4700 Additional results hidden. Use --all to see them. pwndbg> canary --all AT_RANDOM = 0x7fffffffe3a9 # points to global canary seed value TLS Canary = 0x7ffff7ee3828 # address where canary is stored Canary = 0xc4049b4e3a9f4700 (may be incorrect on != glibc) Thread 1: Found valid canaries. 00:0000│ 0x7fffffffb528 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffb768 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffb848 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffb998 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffbae8 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffdad8 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffdae8 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffdf08 ◂— 0xc4049b4e3a9f4700 00:0000│ 0x7fffffffdfd8 ◂— 0xc4049b4e3a9f4700
glibc 通常把 最低一个字节设为 0。这样一来 canary 的 0 字节会截断字符串,导致难以泄露整个 canary。
编译选项
GCC / Clang 的 SSP 相关选项:
-fstack-protector对“看起来危险”的函数插 canary:
- 有较大局部数组(> 8 字节)
- 调用了
alloca - 等等(有个 heuristic)。
-fstack-protector-strong(很多发行版默认)比
-fstack-protector严格,会覆盖更多函数,包括:- 有局部数组;
- 取了局部变量地址;
- 某些其它模式。
-fstack-protector-all- 所有函数都插 canary,最狠也最慢。
-fno-stack-protector显式关掉当前编译单元里的 SSP:
1
gcc -fno-stack-protector a.c -o a
但注意几点:
- 这个只对 你正在编的 .c 文件 生效;
- 系统库(libc 等)本身是单独编译的,即使你关了,你调用的库函数内部依然可能有自己的 canary;
- 某些函数可以带
__attribute__((stack_protect))/__attribute__((stack_protect_strong))之类属性,会覆盖编译选项。
NX(No-eXecute)
NX = No-eXecute bit,是 CPU 页表里的一个硬件位:
- 在 x86 上,它是页表项里的“不可执行标志”(AMD 叫 NX、Intel 叫 XD)。
- OS(Linux、Windows 等)如果支持 NX,就可以在某一页的 PTE 上把 NX 位置 1,表示“这页只能当数据用,不能取指执行”。
- CPU 取指到标了 NX 的页,会直接触发异常(Linux 下就是 segfault),而不是执行里面的内容。
所以从硬件和内核角度看,NX 做的是:
把虚拟地址空间里的“可执行代码”和“纯数据”区域区分开。
常见的安全效果:栈、堆、全局变量这些“用户可控数据”页默认都是 RW / 不可执行;
编译选项
现代 Linux + gcc 一般 默认就是 NX 打开的,也就是说:
- CPU 支持 NX;
- kernel 会把栈、堆、bss 都设置成非执行;
- GCC/ld 产生的 ELF 默认会加
PT_GNU_STACK: R W(非 X)。
关闭 NX 保护的方法有:
方法 1:编译时加 -z execstack
-z 是链接器(ld)的选项,gcc 会帮你转发过去:
1 | gcc a.c -z execstack -o a |
这样:
- 链接出来的 ELF 会把
PT_GNU_STACK标成RWE(栈可执行);([novafacing][8]) - loader 加载时就会给你分配一个可执行栈;
checksec会显示NX disabled(从 CTF 视角就是“可以往栈上打 shellcode 跳过去了”)。
方法 2:对现成的 binary 用 execstack 工具修改
有 execstack 这个小工具可以改已经编好的 ELF:
1 | execstack -q ./a # 看栈是否可执行 |
这个实质就是在改 ELF 里的 PT_GNU_STACK 权限标志。
原理解释
大部分版本的 checksec / pwn checksec 的 NX 一栏,做的事情都是类似:
读取 ELF 的 program header;
找到
PT_GNU_STACK这个条目;看它的
p_flags里有没有PF_X(可执行)位:- 如果
GNU_STACK是RW→NX enabled(栈不可执行); - 如果
GNU_STACK是RWE→NX disabled(栈可执行)。
- 如果
所以:
checksec 的 “NX disabled” 其实只说明“栈是可执行的”,完全不保证“堆也可执行”。
早期很多内核(2.6/3.x 到较老的 4.x)上,有这么一段逻辑(fs/binfmt_elf.c 中 load_elf_binary):
解析
PT_GNU_STACK,算出executable_stack是ENABLE_X / DISABLE_X / DEFAULT;调用
elf_read_implies_exec(ex, executable_stack):1
2如果返回 true,就给当前进程 personality 加上标志
READ_IMPLIES_EXEC:1
2if (elf_read_implies_exec(loc->elf_ex, executable_stack))
current->personality |= READ_IMPLIES_EXEC;
这个 READ_IMPLIES_EXEC 在 do_mmap_pgoff() 里有特殊处理:
1 | /* Does the application expect PROT_READ to imply PROT_EXEC? */ |
也就是说:
只要进程开了
READ_IMPLIES_EXEC,**所有用PROT_READ映射的页都会自动加上PROT_EXEC**——堆、数据段全部变成 RX 或 RWX。
而老版本内核里,**只要你把 PT_GNU_STACK 设为可执行(-z execstack 或 execstack)就会触发 READ_IMPLIES_EXEC**。
结果就是你在老 Ubuntu 上看到的效果:
- 用
-z execstack编译; - checksec 显示 “NX disabled”(栈可执行);
- 实际上 heap / .data 也都变可执行:因为所有 R 页被自动加了 X。
后来大家都觉得这种行为太危险,于是内核做了改动:
- 在 x86‑64 上,**不再因为
PT_GNU_STACK就自动开启READ_IMPLIES_EXEC**; - 默认策略改成“除非显式要 PROT_EXEC,否则所有匿名映射都是 NX”。
在 Linux 5.8-rc1 之后,READ_IMPLIES_EXEC 在 x86‑64 上被禁用,即使 PT_GNU_STACK 设置了 PF_X 也不会再让所有页都可执行。所以在 新一点的 Ubuntu(内核 5.8+,比如 20.04 更新后、22.04 这些) 上:
-z execstack/ execstack:- 只会把 栈段 映射成 RWE;
- 不再触发
READ_IMPLIES_EXEC;
- 堆还是按正常方式通过
mmap(PROT_READ|PROT_WRITE)创建 → RW,但没有 X;
PIE(Position Independent Executable)
没有 PIE 时,可执行文件的 .text 段通常加载在一个固定基址(如 0x400000)。
pwndbg> vmmap
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
Start End Perm Size Offset File (set vmmap-prefer-relpaths on)
0x400000 0x401000 r--p 1000 0 pwn
0x401000 0x402000 r-xp 1000 1000 pwn
0x402000 0x403000 r--p 1000 2000 pwn
0x403000 0x404000 r--p 1000 2000 pwn
0x404000 0x405000 rw-p 1000 3000 pwn
0x7ffff7c00000 0x7ffff7c28000 r--p 28000 0 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7c28000 0x7ffff7dbd000 r-xp 195000 28000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7dbd000 0x7ffff7e15000 r--p 58000 1bd000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e15000 0x7ffff7e16000 ---p 1000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e16000 0x7ffff7e1a000 r--p 4000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e1a000 0x7ffff7e1c000 rw-p 2000 219000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e1c000 0x7ffff7e29000 rw-p d000 0 [anon_7ffff7e1c]
0x7ffff7fa6000 0x7ffff7fa9000 rw-p 3000 0 [anon_7ffff7fa6]
0x7ffff7fbb000 0x7ffff7fbd000 rw-p 2000 0 [anon_7ffff7fbb]
0x7ffff7fbd000 0x7ffff7fc1000 r--p 4000 0 [vvar]
0x7ffff7fc1000 0x7ffff7fc3000 r-xp 2000 0 [vdso]
0x7ffff7fc3000 0x7ffff7fc5000 r--p 2000 0 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fc5000 0x7ffff7fef000 r-xp 2a000 2000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fef000 0x7ffff7ffa000 r--p b000 2c000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffb000 0x7ffff7ffd000 r--p 2000 37000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffd000 0x7ffff7fff000 rw-p 2000 39000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffffffde000 0x7ffffffff000 rw-p 21000 0 [stack]
0xffffffffff600000 0xffffffffff601000 --xp 1000 0 [vsyscall]
PIE 的思路是把可执行文件本身也编译成位置无关代码(PIC),让它像共享库一样,可以被加载到任意地址,并结合内核的 ASLR 随机化基址。
pwndbg> vmmap
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
Start End Perm Size Offset File (set vmmap-prefer-relpaths on)
0x555555554000 0x555555555000 r--p 1000 0 pwn
0x555555555000 0x555555556000 r-xp 1000 1000 pwn
0x555555556000 0x555555557000 r--p 1000 2000 pwn
0x555555557000 0x555555558000 r--p 1000 2000 pwn
0x555555558000 0x555555559000 rw-p 1000 3000 pwn
0x7ffff7c00000 0x7ffff7c28000 r--p 28000 0 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7c28000 0x7ffff7dbd000 r-xp 195000 28000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7dbd000 0x7ffff7e15000 r--p 58000 1bd000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e15000 0x7ffff7e16000 ---p 1000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e16000 0x7ffff7e1a000 r--p 4000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e1a000 0x7ffff7e1c000 rw-p 2000 219000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e1c000 0x7ffff7e29000 rw-p d000 0 [anon_7ffff7e1c]
0x7ffff7fa6000 0x7ffff7fa9000 rw-p 3000 0 [anon_7ffff7fa6]
0x7ffff7fbb000 0x7ffff7fbd000 rw-p 2000 0 [anon_7ffff7fbb]
0x7ffff7fbd000 0x7ffff7fc1000 r--p 4000 0 [vvar]
0x7ffff7fc1000 0x7ffff7fc3000 r-xp 2000 0 [vdso]
0x7ffff7fc3000 0x7ffff7fc5000 r--p 2000 0 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fc5000 0x7ffff7fef000 r-xp 2a000 2000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fef000 0x7ffff7ffa000 r--p b000 2c000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffb000 0x7ffff7ffd000 r--p 2000 37000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffd000 0x7ffff7fff000 rw-p 2000 39000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffffffde000 0x7ffffffff000 rw-p 21000 0 [stack]
0xffffffffff600000 0xffffffffff601000 --xp 1000 0 [vsyscall]
原理解释
先分清两个词:
PIC(Position-Independent Code)位置无关代码
一段 代码 写得比较讲究,里面不直接写绝对地址,而是通过相对寻址 / GOT / PLT 等方式访问数据和函数,所以这段代码被装到内存里的哪个地址都能正常跑。共享库.so通常就是 PIC。PIE(Position-Independent Executable)位置无关可执行文件
指整个 可执行文件 都是由 PIC 编出来的,链接成一种特殊的 ELF:Type: DYN(看起来像一个带入口点的共享库)。这样它就可以像.so一样被加载到任意基址,然后做重定位、执行。
通俗一点说:
PIC:一段代码随便放哪都能跑。
PIE:整个主程序都是 PIC,所以主程序整体随便放哪都能跑。
在安全方向上,PIE 的意义就是:给 ASLR 一个“能搬的主程序”。
编译选项
GCC 的典型组合是:
1 | # 显式开启 |
-fPIE:编译阶段,生成适合做 PIE 的对象代码(类似-fPIC,但稍微弱一些,只保证作为可执行文件足够)。-pie:链接阶段,生成 ET_DYN + PIE 的可执行文件。
在“默认开启 PIE” 的系统(比如现代 Ubuntu)里,如果你想要“传统非 PIE”:
1 | # 新版 gcc: |
关掉之后,readelf -h 的 Type 就会回到 EXEC,程序 .text 基址固定为 0x400000 左右。
⚠ 整个 PIE / 非 PIE 属性是“编译 + 链接期”决定的,没法简单靠
patchelf这种后期改改 header 就切换,因为里面的代码生成方式(是否 RIP‑relative / GOT 引用)已经完全不一样。
传统 -static 静态链接出来的是非 PIE 的 ET_EXEC,主程序基址固定,ASLR 对代码段无能为力。真正的 static‑PIE(-static-pie)需要 glibc/toolchain 专门支持,不是随便加个 -static -pie 就有。
Ubuntu 22.04 的 glibc 版本是 2.35,但默认构建**没有启用
--enable-static-pie**(至少 x86_64 上是这样),也就是说:
/usr/lib/x86_64-linux-gnu/libc.a仍然是为非 PIE 静态程序准备的;- 用的是传统的
crt1.o/crtbeginT.o,这些 .o 内部包含了非 PIC 的绝对重定位(比如对__TMC_END__的R_X86_64_32)。当 GCC/ld 试图干两件事:
- 把输出当成一个 PIE/共享对象 来处理(因为有
-static-pie,等价于告诉 ld “我要做 ET_DYN 风格的程序”);- 又因为有
-static+ 当前 glibc 没 static‑PIE 支持,它只能拉进来老式的crtbeginT.o等非 PIC 对象。结果 ld 一看:
“你这个输入对象
crtbeginT.o含有R_X86_64_32这种绝对 32 位重定位,
但目标明明是 PIE(相当于共享库),不允许这种重定位,
请用 -fPIC 重编译。”因此会报错:
2
3
4
5
R_X86_64_32 against hidden symbol `__TMC_END__' can not be used when
making a PIE object
/usr/bin/ld: failed to set dynamic section sizes: bad value
collect2: error: ld returned 1 exit status
ASLR
ASLR(Address Space Layout Randomization) 是操作系统提供的一种内存保护机制:
每次程序启动时,把以下这些东西的位置随机化:
- 栈(stack)
- 堆(heap)
- 通过
mmap映射的区域(包括共享库) - vDSO(用户态的小 syscall 页)
- 主程序代码段 / 数据段(前提:是 PIE)
在 Linux 上:
- 内核 负责给各种映射挑一个随机基址;
- ELF loader(动态链接器
ld-linux.so) 负责把 PIE / 共享库搬到这些随机基址上。
所以 ASLR 不是编译器一个选项就能搞定的,是内核 + 动态链接器 + 程序编译方式一起配合的结果。
随机化级别
Ubuntu 官方安全文档把 ASLR 具体随机的地址拆成几类(其实主流 Linux 都类似):
- Stack ASLR :每次程序启动,栈顶(
rsp初始值)附近的映射基址都不一样;环境变量、argv 这些其实都塞在栈映射里,也跟着换位置; - vDSO ASLR :vDSO(
linux-vdso.so.1)是内核映射进用户态的一小块“共享库”,里面有gettimeofday、clock_gettime之类的无陷入 syscall 封装;内核也会把 vDSO 映射到随机位置,避免“跳转到 vDSO 某个固定偏移执行 gadget 这类攻击。 - Libs / mmap ASLR :所有通过
mmap得到的匿名映射、共享库(libc.so.6、libm.so.6等)都会随机映射到地址空间的某个地方; - Exec ASLR :如果程序是用
-fPIE -pie编译/链接的,内核和动态链接器会像对待共享库那样,给它一个随机的基址,然后再把.text/.data映射上去;前提:主程序是 PIE(ET_DYN); - brk / heap ASLR :Linux 上小 malloc 通常走
brk这块“向上长”的堆区域(大块用mmap),在 ASLR 完全开启(randomize_va_space = 2)时,内核会让 brk 起点相对于 exec 区的偏移也是随机的。
ASLR 的内核总开关是 /proc/sys/kernel/randomize_va_space,值有 3 种:
0– 关闭 ASLRTurn the process address space randomization off.
所有进程:栈、堆、共享库、vDSO 等 地址都固定;
1– 部分随机(不含 heap/brk)Make the addresses of mmap base, stack and VDSO page randomized.
This implies that shared libraries will be loaded to random addresses.
Also for PIE-linked binaries, the location of code start is randomized.随机项:
- 栈
- vDSO
mmap基址 → 共享库、匿名映射等- 对 PIE 程序,代码段基址也会随机
不随机:
brk堆起点(兼容某些古早 libc5 程序)
2– 完全随机(包括 heap/brk)Additionally enable heap randomization.
在模式 1 的基础上,brk 堆起点也随机,这是现代发行版默认模式(CONFIG_COMPAT_BRK 关闭时)。
修改 ASLR 的命令如下:
1 | # 全局关闭 ASLR(root) |
ASLR 和 PIE 的关系:
一句话总结:
ASLR 是“我要随机化地址”的策略,
PIE 是“主程序本身允许被搬来搬去”的技术。
非 PIE(ET_EXEC)程序
链接时假定程序从一个固定基址(比如
0x400000)运行,内部使用绝对地址。这是因为内核没法随便给你挪基址,否则所有绝对引用都错了;所以即使randomize_va_space=2,主程序.text仍然固定,ASLR 只能随机库/栈/堆。PIE(ET_DYN)程序
链接时使用 位置无关代码(PIC):内部都是基址 + offset,没硬编码绝对虚拟地址;动态链接器把它当成一个“主程序用的 shared object”,选一个随机基址,把所有段映射进去;于是:
- ASLR 打开时:主程序、libc、堆、栈全随机;
- ASLR 关闭时:会选一个固定的基址(比如很多 64 位 Ubuntu 上是
0x55xxxxxxx000),但每次都一样。
Linux 还提供了两个更具体的 sysctl:
vm.mmap_rnd_bits:控制 64 位进程(本机架构) 做 mmap 时使用多少位随机偏移。vm.mmap_rnd_compat_bits:控制 兼容模式进程(比如 64 位内核上的 32 位程序) mmap 的随机位数。
这两个值决定了“mmap 区域基址要随机多少 bits”,受架构支持的最大值限制。主线 Linux 默认大概是:64 位 28 bit、32 位 8 bit,可以调高到:64 位 32 bit,32 位 16 bit。
来看 x86 的源码,内核是怎么用
mmap_rnd_bits的(删掉无关部分):
2
3
4
5
6
7
8
9
unsigned long arch_mmap_rnd(void)
{
unsigned long rnd = get_random_long();
/* 取低 mmap_rnd_bits 比特作为“随机页号”,再左移 PAGE_SHIFT */
rnd &= (1UL << mmap_rnd_bits) - 1;
return rnd << PAGE_SHIFT; // PAGE_SHIFT = 12,页大小 4 KiB
}然后 top‑down 布局的大致逻辑是:
2
addr = align_down(addr, PAGE_SIZE); // 至少 4K 对齐所以:
mmap_rnd_bits = 28的意思是——在 4K 页粒度上最多有 2²⁸ 种不同的位置可以选。
但最后你能看到多少不同的地址,还要看:
- 地址空间窗口多大(
DEFAULT_MAP_WINDOW/TASK_SIZE限制);- 后面有没有再做更粗的对齐(比如 THP 2MiB 对齐)。
用户空间布局
x86_64 的用户空间理论上是:0x0000000000000000 - 0x00007fffffffffff
内核用一个 DEFAULT_MAP_WINDOW 代表 mmap 可用的窗口:
1 | // arch/x86/include/asm/page_64_types.h |
PIE(ET_DYN + INTERP 的可执行文件)加载时用 ELF_ET_DYN_BASE 作为基点:
1 | // arch/x86/include/asm/elf.h |
对于 64 位进程来说,ELF_ET_DYN_BASE ≈ 2/3 * 0x7ffffffff000 ≈ 0x555555554000,所以:
大部分 64 位 PIE 主程序的基址(没开 ASLR 时)就是 0x555555554000 一带,
开了 ASLR 后会在这一段附近加随机偏移。
堆一般是紧跟着 data/bss 往高地址扩展,也在差不多的区域,所以你在旧系统看到:
- PIE / 堆地址 ≈
0x55xxxx... - 共享库(libc 等)贴近用户空间顶部 ≈
0x7fxxxx...
在 内核 5.18 之前,典型情况是:
- mmap 区、库、PIE 基址都以 4K 对齐;
vm.mmap_rnd_bits ≈ 28,随机偏移范围大概是2^28 * 0x1000 ≈ 1 TiB;
但因为:
- 共享库被限制在用户空间最顶端附近(0x7f… 那一截);
- PIE 被限制在
ELF_ET_DYN_BASE ≈ 0x5555...附近;
所以随机实际上只在“中间几十 bit”抖动,高 8 位几乎不怎么变——肉眼看,就像是:
- libc 总是
0x7fxxxxxx... - PIE/堆 总是
0x55xxxxxx.../0x56xxxxxx...
Linux 5.18 开始,为了更好利用 Transparent Huge Pages(THP),对一些映射做了改动:大于等于 2 MiB 的映射会通过 thp_get_unmapped_area() 选地址,并被强制按 2 MiB 对齐。
0x77f111000000 0x77f111028000 r--p 28000 0 /usr/lib/x86_64-linux-gnu/libc.so.6
0x77f111028000 0x77f1111bd000 r-xp 195000 28000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x77f1111bd000 0x77f111215000 r--p 58000 1bd000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x77f111215000 0x77f111216000 ---p 1000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x77f111216000 0x77f11121a000 r--p 4000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x77f11121a000 0x77f11121c000 rw-p 2000 219000 /usr/lib/x86_64-linux-gnu/libc.so.6
当你用
mmap映射一个文件(比如 libc.so.6),如果映射的长度 ≥ 2 MiB,并且文件系统是 ext4/btrfs/xfs 等“主流盘”,内核会尝试把这个映射放在一个 2 MiB 对齐的虚拟地址上,为了以后可以用 2 MiB huge page(透明大页)来映射它。
内核在决定 mmap 要放哪的时候,会调用
get_unmapped_area()这一类函数。从 Linux 5.18 开始,对 ext4/btrfs/xfs 等文件系统,**文件映射会先走
thp_get_unmapped_area()**,而不是直接用原来的get_unmapped_area。
thp_get_unmapped_area()里实际会调用__thp_get_unmapped_area(..., PMD_SIZE),其中PMD_SIZE在 x86‑64 上就是 2 MiB,最后把地址ALIGN到 2 MiB 边界:
2
3
4
5
6
7
8
9
10
11
12
13
unsigned long thp_get_unmapped_area(struct file *filp,
unsigned long addr,
unsigned long len,
unsigned long pgoff,
unsigned long flags)
{
...
ret = __thp_get_unmapped_area(filp, addr, len, off, flags, PMD_SIZE);
if (ret)
return ret;
return current->mm->get_unmapped_area(filp, addr, len, pgoff, flags);
}2 MiB huge page的本质:像 4 KiB 页要 4 KiB(2¹²)对齐一样,2 MiB huge page 要 2 MiB(2²¹)对齐,所以低 21 位全是 0。
对 64 位库(≥2 MiB),原本库基址有 ~28 bit 随机。被 2 MiB 对齐后,损失了 9 bit(因为多出了 2^9 ≈ 512 个页对齐),有效熵只剩 ~19 bit。
只有「大于等于 2MiB 的 file‑backed 映射」会被 THP 对齐,小块 mmap 正常按 4K 对齐随机。
再结合 vm.mmap_rnd_bits 提高(很多发行版把它从 28 调到 30/32):
- 原来随机基本只在某个小区间抖动,高位几乎不动;
- 现在随机偏移范围更大,高 8bit 本身也在一个区间里变化,程序地址变成了
0x55/0x56/0x57,甚至0x5c/0x6x之类的开头,libc 地址也同理。
总结来说就是:
64 位:老内核上 mmap/库/PIE 基本都有 ≈28 bit 熵;5.18+ 之后,大库因 THP 变成 ≈19 bit,某些发行版把 vm.mmap_rnd_bits 调高到 32,又把库拉回 ≈23 bit,其它非 THP 区域可到 32 bit。
32 位:老内核上库/PIE 也就 8 bit,heap 13 bit,栈 19 bit;5.18+ 后 2MiB 的大库甚至掉到 0 bit,靠拉高 vm.mmap_rnd_compat_bits 最多救到 7 bit,整体仍然非常脆弱。
| 区域 / 对象 | 老内核(无 THP 2MiB 对齐,rnd_bits≈28) |
新内核默认(THP 对齐 + rnd_bits≈28) |
新内核 + 高熵(THP 对齐 + rnd_bits=32) |
说明 |
|---|---|---|---|---|
| PIE 主程序 text(ET_DYN) | ~28 bit;约 bit12–bit39 | 仍 ~28 bit;bit12–bit39 | 若 rnd_bits=32:~32 bit;约 bit12–bit43 |
PIE 映射本身通常不是 2MiB 对齐的“巨大映射”,所以不受 THP 影响,熵主要由 mmap_rnd_bits 决定。 |
| 共享库 / libc(大于 2MiB) | ~28 bit;bit12–bit39 | 19 bit;约 bit21–bit39 | 32−9=23 bit;约 bit21–bit43 |
5.18+ 起,大库按 2MiB 对齐 ⇒ 吞掉 9 个随机位。提高 rnd_bits 只能部分弥补。 |
| 小型共享库 / 小 mmap | ~28 bit;bit12–bit39 | 仍 ~28 bit;bit12–bit39 | 若 rnd_bits=32:~32 bit;bit12–bit43 |
只有「大于等于 2MiB 的 file‑backed 映射」会被 THP 对齐,小块 mmap 正常按 4K 对齐随机。 |
| heap(brk),非 PIE | ~13 bit;约 bit12–bit24 | 还是 ~13 bit | 同 | 不走 mmap 区,THP 对齐不直接影响。 |
| heap(brk),PIE 程序 | ~28 bit;bit12–bit39 | 仍 ~28 bit | 若 rnd_bits=32 可略增(视实现而定) |
Heap (PIE) ≈ 28 bit。是否受 rnd_bits 影响略复杂,但和大库 THP 无关。 |
| 用户栈(stack)基址 | ~30 bit;约 bit12–bit41 | 仍 ~30 bit | 变化不大 | 栈随机有自己一套逻辑,与 mmap_rnd_bits/THP 的关系较弱 |
| 区域 / 对象 | 老内核 32 位(无 THP,对应 compat_bits≈8) |
新内核默认(THP + compat_bits≈8) |
新内核 + 高熵(THP + compat_bits=16) |
说明 |
|---|---|---|---|---|
| PIE 主程序 text(ET_DYN) | ~8 bit;约 bit12–bit19 | 仍 ~8 bit | 若 compat_bits=16:~16 bit |
|
| 共享库 / libc(≥2MiB) | ~8 bit;bit12–bit19 | ≈0 bit(几乎固定) | 理论上 ≈7 bit(16−9) | 32 位上大库 + 2MiB 对齐 ⇒ 没啥地方可随机,很多发行版几乎 0 bit 熵。把 compat_bits 拉到 16,最多也就 7 bit 左右。 |
| 小型共享库 / 普通 mmap | ~8 bit;bit12–bit19 | 仍 ~8 bit;bit12–bit19 | 若 compat_bits=16:~16 bit |
小映射不受 THP 影响,熵完全由 vm.mmap_rnd_compat_bits 决定。 |
| heap(brk) | ~13 bit;bit12–bit24 | 仍 ~13 bit | 同 | |
| 栈(stack)基址 | ~19 bit;bit12–bit30 | 仍 ~19 bit | 差别不大 | |
| VDSO / 小映射 | ~8 bit;bit12–bit19 | 仍 ~8 bit | 若高熵:~16 bit | 也走 mmap 区,服从 vm.mmap_rnd_compat_bits。 |
FORTIFY
FORTIFY 不是像 NX / RELRO 那样的“内核级保护”,而是 glibc + GCC 合作实现的一套“带边界检查的 libc 包装函数”。
它靠 _FORTIFY_SOURCE 宏 + 优化编译,在编译期 / 运行时对 strcpy / memcpy / sprintf 这类函数做额外检查,出问题就直接 abort()。
原理解释
这个机制的大致思路是:
在 glibc 头文件 里(如
<string.h>,<stdio.h>),一旦检测到:- 使用 GCC;
- 开了优化(
-O1及以上); - 并且定义了
_FORTIFY_SOURCE>0;
就把一些“危险”函数,比如:
1
2
3strcpy, stpcpy, strcat, sprintf, vsprintf,
memcpy, memmove, memset,
read, pread, getcwd, gets(老版本)...宏替换成带
_chk后缀的版本,例如:1
2
3
4编译后链接到 glibc 里的实现:
__strcpy_chk,__memcpy_chk,__sprintf_chk等。这些
_chk版本在内部会检查“你要拷贝的字节数”是否超过“目标缓冲区大小”:- 编译期能确定一定越界 → 编译器直接给 warning/甚至 error;
- 确定不了或只知道“可能” → 在运行时
_chk里判断,大于就调用__fortify_fail(),程序直接abort()。
当 _FORTIFY_SOURCE 生效时,glibc 的头文件会用宏 / inline 函数把一些“危险函数”替换成带额外参数的版本,比如 strcpy:
1 |
编译后链接到 glibc 里真正实现的 _chk 版本,例如 __strcpy_chk。memcpy / sprintf 等同理:
1 | __builtin___memcpy_chk(dst, src, len, __builtin_object_size(dst, 0)); |
glibc 手册的说法是:
Fortified 变体一般是在原函数名两边加前缀
__和后缀_chk:如__memcpy_chk、__strcpy_chk;
对printf家族和open家族有一些命名上的例外(_2后缀、_chkieee128等)。
这些 _chk 函数内部做的事,大致就是:检查目标对象大小,如果要写的长度超过了,就调用 __fortify_fail()。例如(伪代码,逻辑与 glibc 源码一致):
1 | void *__memcpy_chk(void *dst, const void *src, |
而 __fortify_fail() 最终会走 glibc 的内部错误处理路径,打印诊断信息并触发 SIGABRT(类似 __stack_chk_fail 的行为)。
FORTIFY 的核心依赖是两个内建:
__builtin_object_size(ptr, type)__builtin_dynamic_object_size(ptr, type)(较新,GCC 12+)
编译器会尝试在 编译期 推导指针 ptr 所指向对象的“最大可能大小”(如果完全推不出,就返回 (size_t)-1 表示未知):
1 | char buf[16]; |
glibc fortify 包装里会把这个结果塞给 _chk 版本:
1 | __builtin___strcpy_chk(dest, src, __builtin_object_size(dest, 1)); |
然后就有三种情况:
肯定安全(编译期就能证明确实 fit)
- GCC 看到“长度常量 < 缓冲区大小”,可能会直接退化成普通
strcpy或简单的内联; _chk调用甚至都不会出现在最终二进制里。
- GCC 看到“长度常量 < 缓冲区大小”,可能会直接退化成普通
肯定越界
- GCC 会发出类似
-Wstringop-overflow、-Wformat-overflow等告警; - 在某些配置下(配合
-Werror)直接变成编译失败; - 如果仍然生成代码,运行时一旦触发调用就会走
_chk→__fortify_fail(),程序崩溃。([GNU][2])
- GCC 会发出类似
不确定(只知道上界 / 完全不知道)
- 编译器保留
_chk调用; - 运行时由
_chk自己比较len与dst_objsize,越界则__fortify_fail()。
- 编译器保留
较新的 glibc + GCC 还会在 level 3 使用 __builtin_dynamic_object_size,在涉及 malloc 后又传给 memcpy 的这类场景里推导出更精确的大小。
保护级别
glibc + GCC 主要约定了 3 个等级:
_FORTIFY_SOURCE=1使用
__builtin_object_size做边界检查;如果返回(size_t)-1就不替换函数调用;此外对open/openat的 flags 做一些基本校验。_FORTIFY_SOURCE=2在 1 的基础上增加更 aggressive 的检查,比如
printf家族对%n的限制(只允许出现在只读格式串里)等,有可能会拦截一些标准允许但危险的用法。_FORTIFY_SOURCE=3使用
__builtin_dynamic_object_size做更精确的大小推导。
这一层可能显著增加运行时开销(特别是 size 表达式复杂、调用频繁时),所以默认一般不会开到 3。
glibc 手册列了一长串被 fortify 的函数 / 宏,大致包括:
- 字符串 / 内存:
strcpy/strncpy/strcat/strncat/stpcpy/stpncpy/memcpy/memmove/memset/... printf家族:printf/sprintf/snprintf/vprintf/vsnprintf/...- 文件 I/O:
fgets/fread/getcwd/gethostname/... - 原始 I/O:
read/pread/recv/recvfrom/... open家族:open/open64/openat/openat64/mq_open/...(用_2后缀变体)FD_SET/FD_CLR/FD_ISSET(使用__fdelt_chk)- 宽字符版本:
wcscpy/wcsncpy/wcslcpy/wcslcat/wmemcpy/... - 以及
gets/getwd/syslog/realpath等一堆历史遗留危险函数(很多已经不推荐再用)。
这也解释了为什么 checksec 的 FORTIFY 一栏一般会同时给出两列:
- **
FORTIFY: Enabled/Disabled**:是否在编译时启用了_FORTIFY_SOURCE; Fortified / Fortifiable计数:当前 ELF 里 用了多少个被 fortify 的函数,以及理论上还可以 fortify 多少个没被用到_chk版本。
编译选项
启用 FORTIFY 的最常见写法:
1 | gcc -O2 -D_FORTIFY_SOURCE=2 main.c -o main |
FORTIFY 是否启用由 glibc 的头文件里一个内部宏
__USE_FORTIFY_LEVEL决定,大致逻辑是:
2
3
4
5
6
7
8
9
10
11也就是说,要想 FORTIFY 真正生效,必须同时满足:
- 使用 glibc 头文件(
<string.h>,<stdio.h>,<unistd.h>等);- 编译优化开启:
__OPTIMIZE__ > 0,即-O1及以上;- 定义
_FORTIFY_SOURCE且大于 0;- glibc 自己启用了 FORTIFY 支持(
__GLIBC_USE(FORTIFY),现代发行版基本都开着)。否则即使你写
-D_FORTIFY_SOURCE=2,宏也会被静默降级成“无效”。实战里最常见的组合就是发行版默认 CFLAGS:
-O2 -D_FORTIFY_SOURCE=2(Ubuntu、Debian、Fedora 等都是类似设置)。
关闭 FORTIFY 的最常见写法:
1 | gcc -U_FORTIFY_SOURCE -O2 main.c -o main |
另外如果不满足启用 FORTIFY 保护的条件则同样可以关闭 FORTIFY 保护。
CET
CET = Control‑flow Enforcement Technology,是 Intel 在 x86 上加的一套硬件特性,用来防御 控制流劫持,主要针对:
- ROP:改返回地址,
ret跳到 gadget 链上; - JOP / COOP:改函数指针 / vtable / GOT,间接跳转到奇怪的位置;
CET 在指令集里主要分两块:
- Shadow Stack(SHSTK):影子栈,保护 返回地址(后向边)。
- Indirect Branch Tracking(IBT):间接分支跟踪,限制 间接 CALL/JMP 的落点(前向边)。
你可以粗暴理解为:CET = 硬件级 CFI(控制流完整性)+ 硬件版“栈保护”。
Shadow Stack(SHSTK)
Intel 的官方描述是这样的:
影子栈是一个 单独分配的栈,用户态代码不能直接修改。
当执行CALL时,CPU 同时把返回地址压到 普通栈 和 影子栈。
执行RET时,从两边各弹一个地址,如果不一样,就触发“控制保护异常”(#CP)。
对应硬件上多了几个东西:
一个 SSP(Shadow Stack Pointer)寄存器,指向当前影子栈;
影子栈所在的页面有特殊标记:
- 普通写指令(
mov [mem], reg这种)写不上去; - 只能由 CALL/RET 和几条专门的 CET 指令(
WRSS*、RSTORSSP、SAVEPREVSSP、INCSSP等)改。
- 普通写指令(
开启用户态 SHSTK 之后(内核会给该线程设置 CET MSR 位):
near CALL:
- 像往常一样,把返回地址压到普通栈(
RSP); - 额外再把返回地址压到影子栈(
SSP); SSP向低地址移动(x86 栈向下生长)。
- 像往常一样,把返回地址压到普通栈(
near RET:
- 从普通栈弹出返回地址 A,
RSP += 8(64 位); - 从影子栈弹出返回地址 B,
SSP += 8; - 比较 A 和 B:如果不相等 ⇒ 触发 #CP(Control‑Protection Fault) ⇒ 进程直接挂掉。
- 从普通栈弹出返回地址 A,
所以典型的栈溢出攻击:你只覆盖了普通栈上的 saved RIP,影子栈那一份没法改,一执行 ret 就立即触发 #CP 异常。
Linux 文档里写得很清楚,要用用户态 shadow stack,需要:
- CPU 硬件支持 CET/Shadow Stack(
cpuid里有相关 flag); - 内核配置启用用户态 shadow stack(
CONFIG_X86_USER_SHADOW_STACK之类选项); - 用户态库 / 程序按 CET ABI 构建(带 SHSTK 属性的 ELF)。
Linux 启用流程大致是:
引导时检测 CPU 是否支持 CET;
如果配置打开了 user shadow stack,内核支持为用户进程分配影子栈、设置
MSR_IA32_U_CET之类 MSR;动态链接器(ld-linux)在加载 ELF 时,看到程序或某个 so 的
.note.gnu.property里带 **GNU_PROPERTY_X86_FEATURE_1_SHSTK**,就给这个进程打开 SHSTK:- 分配一块只读+shadow‑stack 类型的内存;
- 初始化 SSP;
- 打开该线程的 CET bit。
文档里还特地提到,当前 64 位 Linux 上:只支持“用户态影子栈 + 内核 IBT”组合,内核自己暂时不用影子栈。
IBT:Indirect Branch Tracking
SHSTK 解决的是“ret 往哪里回”的问题(后向边);但攻击者也可以不碰 ret,而是:
- 改函数指针 / vtable;
- 改 GOT 表;
- 用
jmp [rax]/call [rax]这种 间接跳转 跳到恶意 gadget。
IBT 就针对这种“间接 CALL/JMP 的落点”做限制。
CET 引入了一个新的“landing pad”指令:ENDBRANCH,有两种编码:ENDBR64、ENDBR32。核心点:
编译器会在所有合法的“间接跳转目标”前插入
endbr64;开启 IBT 后:
- 间接 CALL/JMP 必须跳到
endbr开头的地址; - 如果跳到一个不是
endbr的地址(比如半个 gadget) ⇒ CPU 触发#CP,程序崩溃;
- 间接 CALL/JMP 必须跳到
直接 CALL/JMP 不受影响。
和 SHSTK 一样,IBT 也透过 ELF note 宣告“我支持 IBT”:
- ELF
.note.gnu.property里有一个GNU_PROPERTY_X86_FEATURE_1_IBT位; - 链接器通过
-z ibt把这个 property 写进去; - 编译器通过
-fcf-protection=branch或-fcf-protection=full在间接跳转目标插endbr64。
加载器看到 IBT property + 内核/CET 硬件支持,就会给该进程打开 IBT 模式;之后所有非 endbr 开头的间接跳转目标都视为非法。
编译选项
GCC/Clang 这边关键有两个:
IBT:
-fcf-protection==none:关 CET 前向边(默认有些发行版已经改成=full);=branch:只对间接分支插endbr,对应 IBT;=full:在=branch基础上再加ret前的endbr等别的东西,这个对 CET 以外的 CFI 也有帮助。
Shadow Stack:
-mshstk- 允许用一组内建函数操作 shadow stack(
__builtin_*ssp); - 一般应用程序不需要手撸这些,只要链接器/loader 打开 SHSTK,CALL/RET 就会自动维护影子栈;
- 这些选项更多是给 runtime/库实现用的(比如 glibc 的 setjmp/longjmp、信号处理要专门配合 shadow stack)。
- 允许用一组内建函数操作 shadow stack(
Linker 负责在最终 ELF 里写 .note.gnu.property:
-z shstk→ 写入GNU_PROPERTY_X86_FEATURE_1_SHSTK-z ibt→ 写入GNU_PROPERTY_X86_FEATURE_1_IBT- 两个都加 → 一起写,表示这个 ELF 支持/需要 CET 双开。
这样:
- CPU & 内核支持 CET;
- ELF 声明自己是 CET‑compatible;
- loader 自动为该进程打开 IBT + SHSTK,分配影子栈。
判断环境的 CET 支持
已经满足“内核 ≥ 6.6 + glibc ≥ 2.39”的条件,系统级 CET(IBT+SHSTK)才真正开始落地;
看 CPU 支不支持 CET
1
grep -E 'shstk|ibt|cet' /proc/cpuinfo
新一点的 Intel/AMD CPU 会在
flags里出现 CET 相关标志(不同代的名字略有差异)。看内核有没有开用户态 SHSTK / IBT
看内核配置(假设有
/proc/config.gz):1
zgrep -E 'CET|SHADOW_STACK|IBT' /proc/config.gz
在带有 CET 支持的内核树里,文档明确说现在 x86‑64 只支持“userspace shadow stack + kernel IBT”,也就是你主要关心的是:
CONFIG_X86_USER_SHADOW_STACK=y、用户态 IBT 支持是否打开。
另外,Linux 文档里提到可以在 /proc/self/status 里看 per‑thread 特性,比如:
1 | grep x86_Thread /proc/self/status |
远程交互技巧
Pwn 题常见交互类型
大多数 CTF pwn 题可以粗糙归成三类。
xinetd / socat 等 + 0/1/2 重定向
CTF 题目基本都是这种形式——建立接 TCP 链接,然后把这个 TCP socket 接到子进程的 0/1/2 上,最后 exec 题目程序。
例如使用 socat:
1 | socat TCP-LISTEN:9999,reuseaddr,fork EXEC:"./chall",pty,stderr |
过程大概是:
开一个 TCP 监听端口 9999
有人连上来 → fork 一个子进程专门处理
子进程:
- 把这个 TCP socket 和一个 pty 连起来
- 把
./chall的 stdin/stdout/stderr 接到这个 pty 上
./chall还是以为自己在跟一个“终端”交互(因为看到的是 pty),但实际上所有数据都是通过 TCP 传进来的。
inetd / systemd 也是类似,只是配置更复杂。
题目自己写 socket 服务器
有一些题目在 C 代码里自己实现了 socket 通信,形式如下:
1 | int main() { |
对于这类题目我们只能与题目主动建立的 sock 通信,而题目本身的 0/1/2 通常不暴露出来。
而 system() 的行为等价于在子进程里执行:
1 | execl("/bin/sh", "sh", "-c", command, (char *)NULL); |
即:fork + 在子进程 exec /bin/sh -c command
此时子进程会继承父进程所有打开的 fd,包括 0/1/2 和 connfd,但 /bin/sh 只把 0/1/2 当作自己的 stdin/stdout/stderr
此时实际效果是:
- 程序在服务器上确实 fork 出了一个
/bin/sh; - 但这个 shell 正在从 某个本地终端 / /dev/null / 日志管道(fd0)读命令,把输出写到那里(fd1/2);
- **完全没有走你连过来的那个 TCP socket (connfd)**。
所以远程视角就是:
你连上服务 → 发 payload → 程序里
system("/bin/sh")→ 你这边既看不到提示也发不了命令,连接要么卡死,要么被服务端断开。
在“自己写 socket 服务器、只用 connfd 读写”的题里,裸 system("/bin/sh") 通常是拿不到“远程交互 shell”的 —— shell 是开了,但你根本够不到它。
为了能够拿到交互式 shell,我们的思路是要么让 shell 用 connfd 当 0/1/2,要么自己在 shell 命令里做重定向。
QEMU 环境里的用户态 pwn
典型就是各种内核 pwn 环境 / 类内核 pwn 题。一般给你一个 run.sh,里面是类似:
1 | qemu-system-x86_64 \ |
其中 -nographic + console=ttyS0 把 guest 的内核和用户空间的输出都走串口 ttyS0,
这个串口再被重定向到 QEMU 的 stdout / stdin 上。
有的脚本还会用 -serial mon:stdio,同样是把串口控制台绑定到宿主机 stdio。
于是链路就变成:
1 | 你本地的终端 / pwntools |
这和前面第一种的差别在于:
- 你并不是直接连到
/chall的 stdin/stdout 上; - 你是连到了“外面一层的 shell / QEMU console”,中间隔了一层 TTY / pty;
QEMU console 本质上是一个终端设备(串口 → host TTY 或 pty),有:
- 行编辑、回显;
Ctrl+C/Ctrl+Z/Ctrl+D等信号;DELETE、Ctrl+V(LNEXT)等控制字符。
如果你在自己本地的终端里再跑一个 nc,然后再连到远程 QEMU,则某些字符会被远程 TTY 处理掉。
例如发送 \x7f 会被当成 DELETE 键,真的删掉前一个字符。而 64bit glibc 的地址里几乎总有 \x7f 开头的字节,所以如果你直接把 ROP 链扔过去,这个字节会被 TTY 行规吃掉。
解决方法就是用 socat 的 pty escape 字节 \x16 把这些控制字符转义。
重定向
在类 Unix 系统里,每个进程都有一张“文件描述符表”:
0→ 标准输入stdin1→ 标准输出stdout2→ 标准错误stderr
每个 fd 都指向一个“打开文件对象”(open file description),可以是:
- 终端
/dev/tty - 普通文件
- 管道 / socket(pwn 里最常见)
关键点:
多个 fd(比如 0 和 1)可以指向同一个底层对象,这就是
dup / dup2干的事。
dup 重定向
dup/dup2 的语义(man dup2)是:
dup(oldfd)
分配一个新的文件描述符,这个新 fd 指向和oldfd相同的 open file description,
并且保证“新 fd 是当前进程中最小的那个空闲 fd”。
dup2(oldfd, newfd)
做的事跟dup一样,但不是“找一个最小空闲 fd”,
而是强制让newfd变成oldfd的副本。
如果newfd之前已经打开,则先静默close(newfd)。
如果newfd == oldfd,dup2直接什么都不做,返回这个 fd。
也就是说:
1 | int newfd = dup(oldfd); |
因此如果是直接 socket 通信而不是重定向 0/1/2 的 pwn 题目,在 shellcode 里经典套路是:
1 | dup2(sock, 0); |
效果就是:
“把 标准输入、标准输出、标准错误 这 3 个 fd 全都指到这个网络 socket 上。”
因为通常在 CTF 环境中 sock 这个文件描述符的值是稳定可预测的,因此完全可以通过这种方法让 shell 的标准输入输出都走你的 socket,你也就得到一个交互 shell。
shell 重定向
有些题目会 close(1) 关闭输出,对于这种场景我们可以通过 shell 重定向让 sdterr 充当 stdout。
在 sh / bash 里,重定向语法有一种是:
1 | [n]>&word |
如果 word 展开为数字 m,语义是:
“把文件描述符 m 所指向的那个对象,复制一份给 n。”
即:让 fd n 变成 fd m 的一个副本。([Stack Overflow][3])
所以:
2>&1:让 stderr(2)变成 stdout(1)的副本(命令的错误输出会跟着标准输出走)。([Super User][4])1>&0:让 stdout(1)变成 stdin(0)的副本。
这不是“把 0 的内容复制一份到 1”,而是把两个 fd 接到同一个东西上,之后:
- 写入 fd 1 → 写入那个底层对象;
- 读 / 写 fd 0 → 也是同一个底层对象。
底层对应的系统调用就是:
1 | dup2(src_fd, dst_fd); // dst_fd 变成 src_fd 的别名 |
比如 1>&0 本质就是 dup2(0, 1)。
exec 在 shell 里有两种用法:
exec /bin/ls:用 ls 替换当前 shell 进程;exec 1>file/exec 1>&0:不带命令,只带重定向 → 修改“当前 shell 自己”的文件描述符。
POSIX / bash 手册里说得很明白:
使用
exec并只带重定向时,这些重定向会修改当前 shell 的文件描述符,而不是新进程。
还有一条:
如果不带参数,
exec只是重定义当前 shell 的文件描述符,执行完后 shell 继续跑,只是之后的 stdin/stdout/stderr 都变了。
所以:
1 | exec 1>&0 |
= “在当前 shell 进程里执行一次 dup2(0, 1),之后这个 shell(以及它之后 fork/exec 出来的子进程)都会继承这个新的 fd 布局”。
如果你写成:
1 | some_cmd 1>&0 |
那只是:some_cmd 这个进程的 stdout 被改成 stdin,对当前 shell 的 fd 没影响,命令结束就归零了。
pwn 里我们想要的是“把 /bin/sh 本身的 stdout 改回来,并且持续生效”,所以要用 exec 1>&0。
另外像 socket 服务器这种类型的题目,由于 system 启的进程可以继承父进程的文件描述符。也就是说我们建立的 socket 也可以被 /bin/sh 继承过去,我们可以采用下面这种方式(假设 socketfd = 4)通过 shell 重定向来获得一个交互式 shell。
1 | system("/bin/sh <&4 >&4 2>&4"); |
不过这种方法成功的前提是 fd 4 没有被 FD_CLOEXEC 掉。
FD_CLOEXEC是一个“文件描述符标志”,名字叫 close‑on‑exec。这个标志跟某个 fd 绑定(比如 fd=4),用fcntl(fd, F_GETFD / F_SETFD)操作。含义是:如果某个 fd 的
FD_CLOEXEC置位(=1),那当这个进程调用任何exec*系列函数成功时,这个 fd 会被内核自动关闭。反之,如果
FD_CLOEXEC没开(=0),那这个 fd 会在execve()之后继续保持打开,被新程序继承。因此只有 fd 4 没有被 FD_CLOEXEC 掉,这样
system()里的/bin/sh才能继承这个 fd。
IO 通信
题目读入函数
| 函数 | 是否读空格 | 截断条件(停止条件) | 自动加 '\0' |
长度控制 | 备注 / 安全提示 |
|---|---|---|---|---|---|
gets(buf) |
✅ 能 | 遇到首个 \n(丢弃该换行)或 EOF |
✅ 是(成功时) | ❌ 无 | 已被 C11 移除,严禁使用;无法限制长度,极不安全。 |
fgets(buf, n, stdin) |
✅ 能 | 读到 \n(保留在缓冲区)、或读满 n-1、或 EOF/错误 |
✅ 是*(若至少读到 1 字节;否则返回 NULL) |
✅ 由 n 限制 |
常见坑:换行会保留;若一开始就 EOF/错误,缓冲区不改动、返回 NULL。 |
scanf("%s", buf) |
❌ 不能(以任一空白为分隔) | 遇到空白字符(空格/\t/\n 等;会跳过前导空白) |
✅ 是*(成功匹配时) | ❌ 默认无;应写宽度如 %Ns |
对 %s 和 %[ 必须写入字段宽度,否则同样不安全;s 会写终止符。 |
scanf("%[^\n]", buf) |
✅ 能 | 遇到 \n(不消费该换行,仍留在输入流中)或达字段宽度 |
✅ 是*(成功匹配时) | ❌ 默认无;应写 %N[^\n] |
扫描集会把空格读入结果;由于不消费换行,后续读取前最好先丢弃该换行。 |
read(fd, buf, size) |
✅ 能 | 读满 size 或 EOF(返回已读字节数) |
❌ 否 | ✅ 由 size 精确控制 |
原始字节读取(系统调用),不会追加终止符;若要当 C 字符串用,需手动补 '\0'。 |
getline(&buf, &len, stdin) |
✅ 能 | 读到 \n(保留在缓冲区)或 EOF/错误 |
✅ 是(成功时) | ✅ 自动扩容(必要时 realloc) |
POSIX 接口(ISO C 未定义);返回字节数(包含换行,不包含终止 '\0')。 |
在 C 语言
Clocale 下,isspace()判定为空白的仅以下 6 个字符(也是scanf/printf相关规则里的空白集合):
- 空格:
' '- 水平制表:
'\t'(HT)- 换行:
'\n'(LF)- 垂直制表:
'\v'(VT)- 换页:
'\f'(FF)- 回车:
'\r'(CR)
shutdown 技巧
close(fd) 会把当前进程里的这个 fd 直接关掉,之后对这个 fd 的读写都会失败;如果这是最后一个指向该 socket 的引用,底层连接也会被内核关闭。
对于 socket,更细粒度地控制可以用 shutdown(sockfd, how):
1 | int shutdown(int sockfd, int how); |
以 TCP 为例:
SHUT_WR:本端写方向关闭- 后续
send/write失败; - 内核向对端发送 FIN,对端继续读,数据耗尽后再读会得到返回值 0(EOF);
- 本端仍可继续
recv对端发送的数据。
- 后续
SHUT_RD:本端读方向关闭- 本端不再接收数据(后续
recv直接失败或返回 0),不会给对端发 FIN; - 对端仍可继续
send,但这些数据会在本端内核中被丢弃。
- 本端不再接收数据(后续
SHUT_RDWR:同时关闭读、写方向,但 fd 仍存在,需要额外close()释放。
在 pwn 里常见的场景是:
1 | while ((n = read(0, buf, sizeof buf)) > 0) |
程序只有在读到 EOF 时才会打印 "bye"。
pwntools 脚本中,如果直接 p.close(),连接会整体结束,收不到 "bye"。
正确做法是半关闭写端:
1 | p.send(payload) |
tube.shutdown(direction) 的语义,就是帮你在后端 socket/pipe 上做 shutdown 或关闭一端的 pipe。其中的的 direction 可以是:
"in","read","recv":关闭“读”方向;"out","write","send":关闭“写”方向。
对远程 TCP 题目,shutdown('send') 最常见,用来触发对端读到 EOF 之后的逻辑(比如结束循环、输出 flag)。
tty 转义绕过
你在本地终端里跑:
1 | $ cat |
然后你敲键盘:
- 敲
a b c→ 终端窗口里看到abc,cat进程也收到字节0x61 0x62 0x63; - 敲
Backspace→ 屏幕上删掉一个字符;cat并没有收到“Backspace”这个按键,而是终端自己把刚刚那一位删掉了; - 敲
Ctrl+C→ 屏幕上出现^C,cat进程被 kill 掉(收到 SIGINT),它根本没读到字节0x03; - 敲
Ctrl+D→cat结束(读到 EOF),并不是收到0x04字节。
重点:在你的程序和键盘之间,还有一层“终端驱动 / 行规(line discipline)”在搞事情。
这层就是 /dev/tty / /dev/pts/N 对应的终端设备,负责:
- 把按键转换成字节流;
- 对某些组合做特殊处理(Ctrl+C → SIGINT,Ctrl+Z → SIGTSTP,Ctrl+D → EOF 等);
- 做行编辑、回显、删除、历史记录等等。
POSIX 里定义了一个控制字符叫 VLNEXT / lnext(literal next),在绝大多数系统上默认是 Ctrl‑V(0x16)。
你可以 stty -a 看配置,会有一行类似:
1 | lnext = ^V; |
意思是:“下一个字符按字面含义处理,不要当控制字符。”
所以在终端里:
直接按
Ctrl+C:终端把这次按键当作“中断键”,发 SIGINT,程序死;按
Ctrl+V然后Ctrl+C:- 终端先看到
Ctrl+V(lnext),切换成“literal next 一次”模式; - 下一次按
Ctrl+C时,不再当成中断,而是真的把字节0x03送给程序; - 程序就能收到
0x03这个字节,而不是被干掉。
- 终端先看到
也正因为如此,在很多文本编辑器里你想插入一个真正的 “Ctrl+S” 字节,常常是
Ctrl+V再按Ctrl+S。
在 CTF 场景中,如果程序的 stdin/stdout 连着的是 /dev/pts/N 这种 TTY 设备;中间那层“终端 driver / line discipline”会截胡控制字符:
- 你发
0x03→ 变成 SIGINT; - 发
0x04→ 被当成 EOF; - 发
0x7f→ 被当成 DEL,删前一个字符(在 canonical 模式);
如果你要做“文件传输 / 传 shellcode / 任意字节流”,这些字节不能被 TTY 吃掉,于是你就希望先发一个 lnext,然后再发控制字符本身。
pwntools 的 tty_escape 就是专门为后面这种场景设计的。Release note 里明确写过:
“Add TTY escape function for file transfer”
该函数实现如下:
1 | def tty_escape(s, lnext=b'\x16', dangerous=bytes(bytearray(range(0x20)))): |
pwntools 的文档这样说:
s (bytes): 要转义的数据lnext (bytes): 用来“引用下一个字符”的字节,默认是^V(0x16)dangerous (bytes): 认为“危险,需要转义”的字节集合
默认参数:
lnext = b'\x16'→ Ctrl‑V;dangerous = bytes(range(0x20))→ 0x00–0x1f 所有 ASCII 控制字符;
也就是说:默认认为所有 0x00–0x1f 都是“危险字符”,要用 lnext 前缀保护起来。
如何使用题目提供的 docker 环境
netcat
在官网下载项目源码,使用如下命令进行编译。
1 | ./configure LDFLAGS=-static # 考虑到 docker 环境恶劣选择静态编译 |
编译后生成的 netcat 位于项目 src 目录下。netcat 即我们常用的 nc 命令对应的可执行程序。
在 docker 中使用如下命令将题目 io 映射到 8888 端口。
1 | ./netcat -lvp 8888 -e ./pwn |
在本机可以使用如下命令连接并交互。(前提是 docker 的 8888 端口映射到本机的 8888 端口)
1 | nc 127.0.0.1 8888 |
gdb
在官网下载项目源码,使用如下命令编译 gdbserver :
1 | sudo apt-get install libgmp-dev libmpfr-dev |
对于 gdb ,由于编译 gdb 时依赖的静态库需要提前编译,因此想要编译 gdb 最好直接编译整个项目:
1 | cd gdb-9.2 |
注意以下几点:
- 编译的
gdbserver版本一定要与本机的gdb匹配,不同版本的gdbserver通信协议不同。 - 有的时候在
gdbserver中运行./configuer命令会出现找不到Makefile的情况,这时在根目录进行一次编译就好了。 - 连接失败之后再运行一次编译命令就可能编译成功。
gdb位于./gdb/gdb中。gdbserver位于./gdbserver/gdbserver中。
docker
加载镜像
1
docker load -i 题目附件.tar
查看现有镜像
1
docker images
启动容器
1
docker run --privileged -it -w /home/ctf -v ~/Desktop/本机目录:/home/ctf/镜像目录 -p 8888:8888 -p 9999:9999 镜像名 /bin/bash
--privileged:加这个参数才能gdbserver附加进程远程调试-v:目录映射,方便传文件。-p:端口映射,开两个端口分别给netcat和gdbserver用。改用--net=host可以映射全部端口。-w:进入 docker 后目录为/home/ctf。
查看现有容器
1
docker ps
进容器 shell ,即同一个容器再开一个 shell 。
1
sudo docker exec -it -w /home/ctf 容器ID /bin/bash
停止所有容器:
1
docker stop $(docker ps -a -q)
删除所有容器:
1
docker rm $(docker ps -a -q)
删除所有镜像:
1
docker rmi $(docker images -q)
使用方法
exp.py 模板如下:
1 | from pwn import * |
运行脚本前首先在 docker 容器中用
netcat将题目程序 IO 映射到 8888 端口:1
./netcat -lvp 8888 -e ./pwn
运行脚本,阻塞在
gdb.attach时脚本已经与远程的netcat连接,此时 docker 镜像中已经有pwn这个进程了。此时使用ps -aux | grep pwn查看进程pid然后运行如下命令让gdbserver附加进程并监听 9999 端口。1
gdbserver :9999 --attach 进程pid
此时脚本执行
gdb.attach连接 docker 中的gdbserver并阻塞在pause()上直到gdb成功连接gdbserver。在脚本运行窗口按回车解除阻塞进行调试。
其中 docker 中的操作可以通过脚本自动化实现。
1 |
|
- Title: linux user pwn 基础知识
- Author: sky123
- Created at : 2024-11-07 18:56:56
- Updated at : 2026-02-03 00:02:59
- Link: https://skyi23.github.io/2024/11/07/linux user pwn 基础知识/
- License: This work is licensed under CC BY-NC-SA 4.0.